





BIVA Data Classificatie
Sommige bedrijven en organisaties deden het al jaren en sommige zijn er pas zeer recent mee begonnen. Dataclassificatie ofwel “rubricering”. Zeker sinds de introductie van verschillende veiligheidsnormen, wetten en eisen zoals de GDPR, AVG, NEN 7510, BIWA, BIO worden bedrijven zich meer en meer bewust van de noodzaak van dataclassificatie. Dataclassificatie zorgt ervoor dat data voorzien wordt van een specifieke classificatie waar weer verschillende soorten technische en organisatorische maatregelen bij horen. In deze post gaan we kort kijken naar dataclassificatie en gaan we een tool ontwikkelen waarmee iedereen data kan classificeren.
Het doel van dataclassificatie hebben we in de intro al verklapt, namelijk het richting geven aan passende technische en organisatorische maatregelen. Bedrijven beschikken vaak over veel soorten gegevens zoals persoonsgegevens, vertrouwelijke gegevens, bedrijfsgeheimen etc. Je wilt dat deze gegeven op een bepaalde manier beschermd worden. Om dit inzichtelijk te maken moet deze data geclassificeerd worden.
Als we het hebben over “data” dan bedoelen we altijd “informatie” maar dan wel in de breedste zin. Denk bijvoorbeeld aan ruwe data en gestructureerde data (databases). Je classificeert dus altijd de informatie en niet de systemen die deze informatie verwerken. De data wordt voorzien van een classificatie en het is aan de organisatie om hier passende systemen en processen bij te creëren die deze data beschermen volgens de normen van de classificatie. Om te kijken of de systemen en processen afdoende zijn om de data op de gewenste manier te beschermen kan een risicoanalyse worden uitgevoerd op de systemen.
Het juist classificeren van data gebeurt altijd door een verantwoordelijke. De classificatie moet namelijk ook ondertekend worden door een verantwoordelijke. In de meeste gevallen is dit de eigenaar van de data of verantwoordelijke van de afdeling die deze data primair verwerkt. De classificatie kan daarnaast, als de verantwoordelijke niet het volledige mandaat heeft om de classificatie uit te voeren ook nog ondertekend worden door de directie om aan te geven dat de classificatie is gecontroleerd en akkoord bevonden is. De directie is immers altijd eindverantwoordelijk als het over bedrijfsdata gaat. In de meeste gevallen zie je dat de verantwoordelijke voor het maken van de dataclassificatie een (proces)manager of een directielid is.
Voor data geclassificeerd moet worden moet je als organisatie vaststellen binnen welke processen deze data “aangeraakt” wordt. Heb je de data niet nodig, vermeid hem dan uit je processen. Wordt de data aangeraakt door afdelingen die hier feitelijk geen inzage in moeten hebben, verander dan je proces. Pas als je in kaart hebt over welke data je beschikt en op welke manier deze gebruikt wordt kun je een goede dataclassificatie uitvoeren.
Belangrijk voordat je kunt gaan classificeren is dus:
- Kritische analyse van processen en data zodat alleen benodigde informatie door de essentiële afdelingen wordt verwerkt.
- Data eigenaren die verantwoordelijk zijn voor de data verwerking en de classificering.
- Inzicht in de wettelijke kaders. Wat eist de wet van mij en mijn data? Mag ik die data wel verwerken en zo ja, op welke voorwaarde? Deze voorwaardes moeten meegenomen worden in de classificatie.
Het toekennen van data classificatie zorgt voornamelijk voor een goede awareness. Men moet bijvoorbeeld rekening houden met het in gebruik nemen van nieuwe systemen omdat data die het systeem gemarkeerd is met een bepaalde data classificatie. Daarnaast zorgt data classificatie voor het voldoen aan diverse certificeringseisen en wetten maar ook voor het snel herstellen van essentiële data in geval van een calamiteit. Ook maakt een goede classificatie het makkelijke om bepaalde tooling zoals Microsoft Azure Information Protection te gebruiken.
Genoeg voordelen, maar uiteraard heeft data classificatie ook diverse nadelen zoals het verhogen van de administratieve lasten om de classificatie up-to-date te houden. Ook zullen implemtatie trajecten vaak langer worden en moet er meer geïnvesteerd worden.
Maar hoe doen we dat dan? Hoe classificeren we data?
BIV Data Classificatie
Het meest gebruikte data classificatie model is het BIV model welke afkomstig is uit de BIG en aangehaald wordt in diverse veiligheidsnormen zoals de AVG en BIWA. De Engelse equivalent hiervan is de CIA triad waarbij de letters staan voor “Confidentiality, Integrity en Availability.”. De letters van de BIV classificatie staan voor:
B – Beschikbaarheid
I – Integriteit
V – Vertrouwelijkheid
Vaak wordt de BIV norm uitgebreid naar een “BIVA” norm. De “A” staat voor:
A – Aantoonbaarheid
En dan hanteren sommige organisaties zelfs nog de BIVA-P classificatie. De extra “P” staat voor:
P – Privacy
De BIVA en BIVA-P classificatienormen zijn geen officiële normen maar bedrijven mogen hun data wel op deze uitgebreide manier classificeren. Hoe duidelijker de classificatie des te beter inzichtelijk is welke maatregelen hier aan verbonden zijn.
Laten we de BIVA-P waardes eens beter verduidelijken:
B – Beschikbaarheid
Beschikbaarheid verteld iets over de beschikbaarheid van de data, hoe snel deze beschikbaar moet zijn en hoe ernstig het is als de data op een gegeven moment niet voorhanden / beschikbaar is.
I – Integriteit
De integriteit verteld iets over de zekerheid op juistheid en de volledigheid van de data. Met andere woorden, hoe belangrijk is het om zeker te weten dat er niet ten onrechte met de data geknoeid is.
V – Vertrouwelijkheid
Hoe vertrouwelijk is de data. We hebben het hier niet over het feit of de informatie wel of geen persoonsgegevens bevat maar over de gevoeligheid van de informatie / inhoud. Wie mogen deze data inzien en wat zijn de gevolgen als de data in handen komt van onbevoegde personen.
A – Aantoonbaarheid
Aantoonbaarheid hangt erg samen met de integriteit maar is toch iets anders. De aantoonbaarheid verteld iets over het belang aan te kunnen tonen dat de data integer is (controleerbaarheid). Denk hierbij aan bijvoorbeeld logs, archivering en audit trails. Als de integriteit hoog is kan de aantoonbaarheid niet laag zijn en meestal zijn deze 2 waarden gelijk aan elkaar. In theorie kan het wel zo zijn dat data een lagere integriteit classificatie heeft met een hogere aantoonbaarheid classificatie.
P – Privacy
De “privacy” norm verteld iets over de privacy gevoeligheid van de gegevens. Feitelijk of de data persoonsgegevens of bijzondere persoonsgegevens bevat.
Persoonlijk vindt ik de P toevoeging overbodig. Wanneer persoonsgegevens en zeker wanneer bijzondere persoonsgegevens voorkomen gelden de normen van een hoog vertrouwelijkheidsniveau en daarbij ook de gekozen maatregelen.
Als we dan kijken naar de BIVA norm dan wordt het zaak om per onderdeel verschillende scores te maken. Zo kun je voor “Vertrouwelijkheid” slechts 3 classificaties kiezen:
- Openbaar
- Alleen Intern
- Vertrouwelijk
Of 5:
- Niet geclassificeerd
- Beperkt verspreid
- Vertrouwelijk
- Geheim
- Zeer Geheim
Als de scores bekend zijn dan kan hier een maatregelenpakket voor gemaakt worden. Bijvoorbeeld:
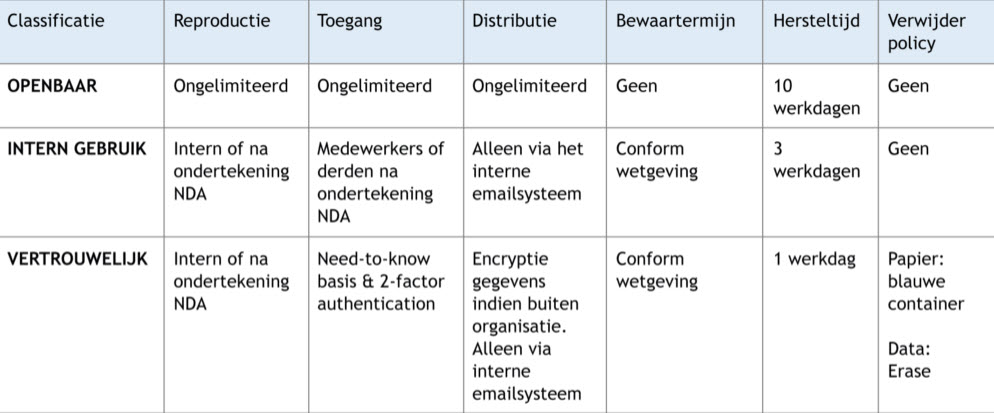
Als de data classificatie bekend is en het pakket is bekend dan kan snel achterhaald worden waar een systeem aan moet voldoen om bepaalde data te mogen verwerken.
Laten we uitgaan van een 4-punts schaal die er als volgt uitziet:
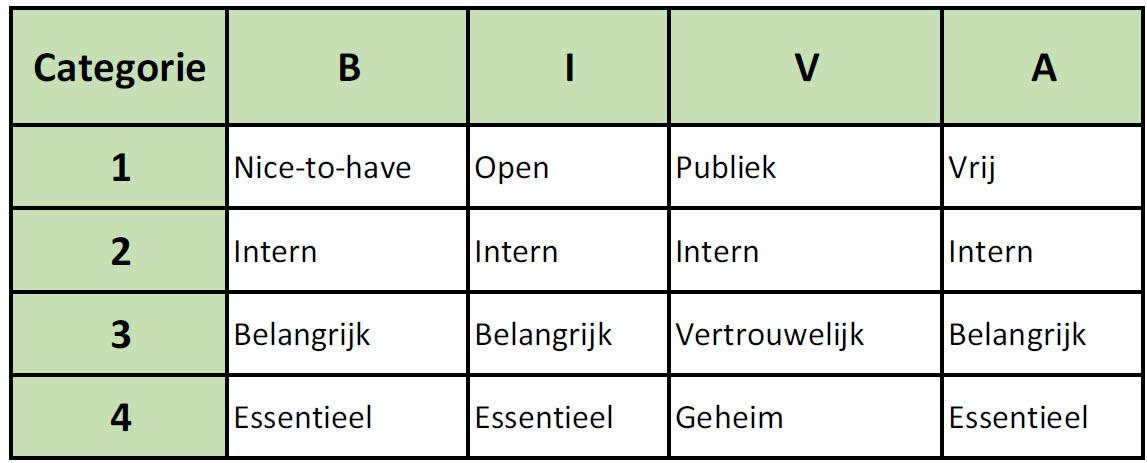
Hier kunnen we vervolgens per score bepaalde maatregelen aan verbinden:
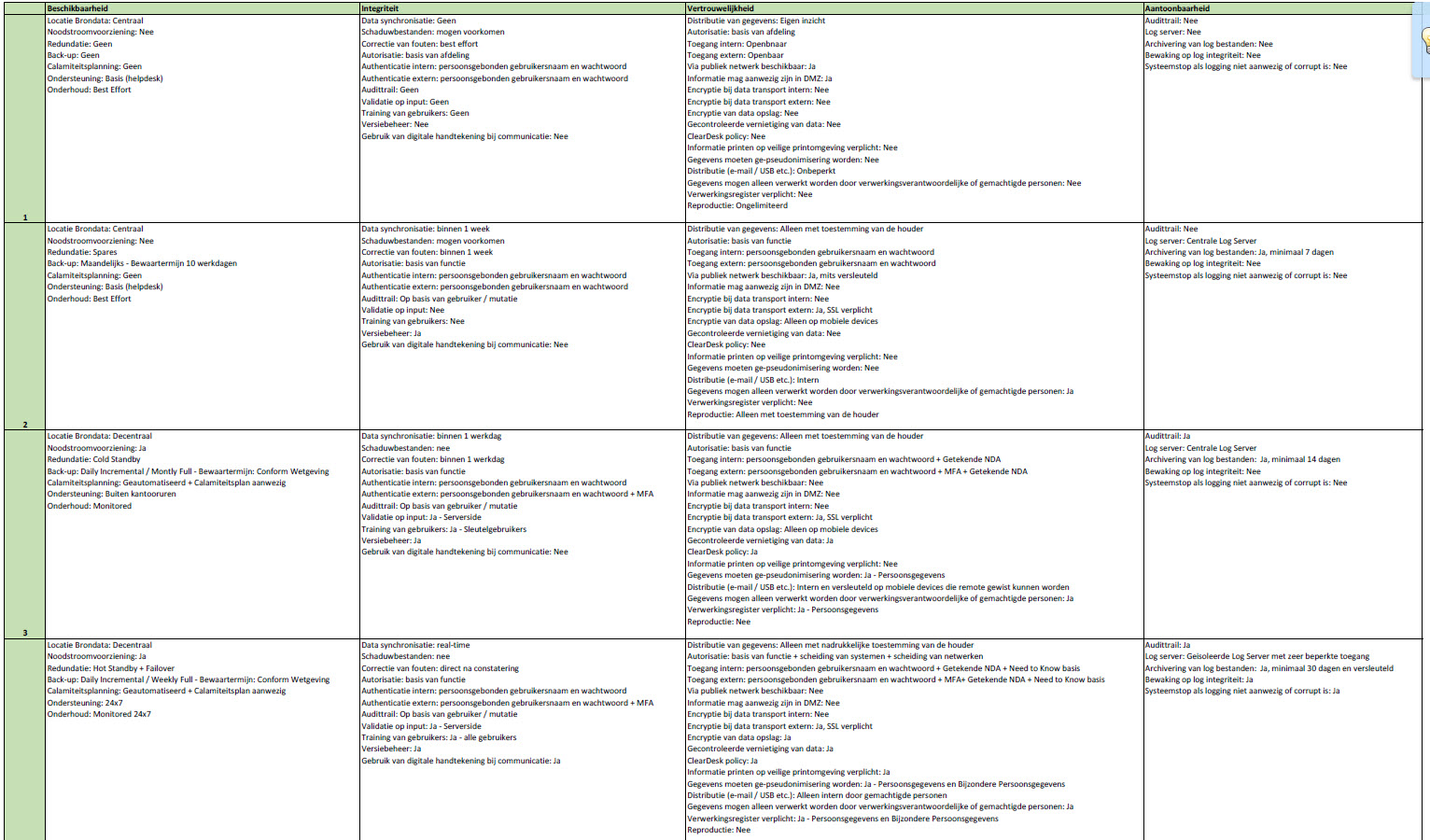
En als de maatregelen duidelijk zijn kan per dataset een classificatielijst worden ingevuld:

Het invullen van de data classificatie is echter niet altijd even gemakkelijk. Je moet exact weten welke data er verwerkt wordt en ook moet je een goed inzicht hebben in het belang van de data. Een 4444 BIVA normering maken is makkelijk en altijd afdoende. Echter moet je ervoor zorgdragen dat de normering past bij de data. Alles 4444 normeren zou betekenen dat processen herzien moeten worden, processen simpelweg onmogelijk worden en dat er erg dure technische maatregelen in het leven geroepen moeten worden.
Juist om dit proces te vergemakkelijken kun je een aantal vragen verzinnen. Door deze vragen te beantwoorden zal de classificatie makkelijker worden. Via “informatieveiligheidsdienst.nl” is een “Handreiking Dataclassificatie” te verkrijgen die u hierbij kan ondersteunen.
Zo kunnen we bijvoorbeeld een vragenlijst per BIVA normering maken en hier eventueel meteen een score door uit laten rekenen:

Uiteraard moet de vragenlijst goed getest en nagekeken worden. Indien gewenst koppel je de uitslag van de vragenlijst meteen aan de BIVA classificatie of je gebruikt hem als leidraad.
Download hier de gehele Excel voor data classificatie zoals gebruikt in bovenstaande voorbeeld.
Uiteraard kunnen we dit hele proces ook automatiseren. Download hier de geautomatiseerde tool die ik even gemaakt heb middels een Python script.
Zoals je ziet is data classificatie geen gemakkelijke aangelegenheid. Het is een proces waarbij alle stakeholders betrokken zijn. Er moet goed nagedacht worden over de normen en de voorwaarden die van deze normen afhankelijk zijn. Data classificatie is niet alleen een papieren aangelegenheid maar moet ook nog nageleefd worden.
Hopelijk vond je deze post interessant en heb ik je wat meer inzicht kunnen geven in het gehele data classificatie proces. Laat het me s.v.p. weten als je deze post interessant vond en like of deel hem ook even op je sociale kanalen. Hiermee help je me om dit soort posts te kunnen blijven maken. Alvast super bedankt!