





Python Scripting like a Boss
De reden waarom Python zo populair is onder de security professionals (pentesters) is o.a. omdat Python een gemakkelijke scripting taal is, veel interessante libraries (requests / urllib) bevat en er veel online tutorials en tips zijn. Daarnaast is Python op vrijwel elk platform geïmplementeerd of gemakkelijk te implementeren. Het is dus logisch dat Python vaak gekozen wordt om zaken te automatiseren. Wanneer je goed bent met Python kun je zelf je eigen applicaties schrijven maar ook wanneer je plots een taak moet automatiseren tijdens beheerwerkzaamheden of een Capture The Flag Challenge is Python de go-to tool. In deze post een aantal interessante libraries met voorbeelden om te kunnen gebruiken zodat jij snel zult scripten “like a Boss”!
We hebben het al vaak over Python gehad. Python zie je veel binnen scripting en tooling en is nog steeds mijn favoriete programmeertaal. Ik werk graag in Powershell en Bash maar Python heeft gewoon nog steeds de voorkeur. En nee, ik ben geen developer en nee… ik ben ook niet extreem snel of goed in Python. Er was echter een tijd dat ik helemaal niet wist hoe ik Python effectief kon inzetten of gebruiken en je merkt dat je, wanneer je er simpelweg meer gebruik van maakt het allemaal een stuk logischer wordt. Daarom hoop ik met deze post ook jou iets meer inzicht te kunnen geven in Python en met name de Python libraries. Ik laat je de meest interessante cybersecurity libraries zien en hoe je deze effectief kunt inzetten. Heb je goede aanvullingen of tips… please let me know!
Binnen deze post hanteer ik primair Python3. Python2 kan in sommige situaties ook zeer handig zijn maar wordt niet meer officieel ondersteund. Daarnaast neem ik aan dat je over de basis beschikt en weet hoe loops werken, wat variabelen zijn etc. Mocht je nog nooit iets met Python gedaan hebben dan raad ik je aan om eerst mijn “Python – Leren programmeren” posts door te lezen.
Binnen deze post behandelen we de volgende libraries:
- urllib
- requests
- Beautiful Soup
- Scapy
- Sockets
- PwnTools
- MechanicalSoup
urllib
De “urllib” library is een speciale library welke het mogelijk maakt om met URL’s (Uniform Resource Locators) te werken in Python. urllib wordt gebruikt om URL’s op te halen middels verschillende protocollen.
Installatie:
pip install urllib |
Modules:
De urllib library bestaat uit een aantal verschillende modules zoals:
- urllib.requests = Voor het openen en lezen van URL’s
- urllib.parse = Voor het parsen van URL’s. Deze module helpt bij het definiëren van functies om URL’s en hun componenten te manipuleren, te bouwen of af te breken. Deze functie is ideaal om te gebruiken bij het splitsen van een URL in kleinere componenten of het samenvoegen van verschillende URL-componenten in de URL-string.
- urllib.error = Voor het afhandelen van fouten
- urllib.robotparser = Voor het parsen van robot.txt bestanden
Voorbeelden:
Het ophalen van een HTTP / HTTPS URL en bekijken van de pagina broncode werkt als volgt:
#! /usr/bin/python import urllib.request url = urllib.request.urlopen('https://jarnobaselier.nl') print (url.read()) |
Het wordt interessanter wanneer je ook zaken met een URL kunt doen. Hiervoor kun je de urllib.parse functie gebruiken. Zo breken we in onderstaande voorbeeld de URL op in verschillende componenten en later voegen we deze weer samen in een URL.
from urllib.parse import * parse_url = urlparse('https://jarnobaselier.nl') print(parse_url) print("\n") unparse_url = urlunparse(parse_url) print(unparse_url) |

urllib is een prima module voor het opvragen van paginainhoud, werken met een robot.txt file en het modificeren van URL strings. Daarnaast is er ook een urllib2 en een urllib3 versie. Het is echter aan te raden om de krachtere “requests” module te gebruiken (die op de achtergrond ook urllib3 gebruikt):
requests
De “requests” library is de standaard voor het maken van HTTP-verzoeken in Python. En kent vele mooie features waaronder:
- Mooie, eenvoudige API.
- Keep-Alive & Connection Pooling
- Internationale domeinen en URL’s
- Sessies met persistense cookies
- Browser-style SSL-verificatie
- Automatische inhoudsdecodering
- Basis / Digest-verificatie
- Elegante key / value cookies
- Automatische decompressie
- Unicode Response Bodies
- HTTP (S) Proxy-ondersteuning
- Multipart bestandsuploads
- Streaming downloads
- Connection Time-outs
- Chucked requests
- .netrc bestandsondersteuning
En dat… is pas het topje van de ijsberg. Deze post raakt slecht een heel klein gedeelte van de mogelijkheden die de requests library zijn gebruikers biedt.
Installatie:
pip install requests |
Voorbeelden:
Laten we eens een normale (GET) request doen en kijken wat we hiervan terugkrijgen:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl') print(request) |
We krijgen statuscode 200 retour wat simpelweg betekend dat de pagina bestaat (OK). Om te werken met de return code kunnen we ook het “.status_code” argument gebruiken:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl') if request.status_code == 200: print('Success!') elif request.status_code == 404: print('Not Found.') |

Maar het is niet perse nodig om status codes te definiëren. De requests library zal “true” genereren als de statuscode tussen de 200-400 zit en anders zal deze “false” retourneren. Op die manier kun je bovenstaande dus makkelijker maken:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl') if response: print('Success!') else: print('An error has occurred.') |
Wanneer je echter benieuwd bent naar de content gebruik je de “.content” module:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl') print(request.content) |

Zoals je kunt zien aan het de b’ prefix zie je hier de ruwe bytes van de respons. Dit is ideaal voor afbeeldingen maar niet voor teksten.
Laten we eens een afbeelding downloaden:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl/wp-content/uploads/2017/11/Jarno-Baselier-Logo5-Wit-300x80.png') print(request.content) with open ('Jarno-Baselier.png', 'wb') as f: f.write(request.content) |
We schrijven nu de inhoud weg in “Jarno-Baselier.png” en we schrijven deze weg als bytes (wb = with bytes).
We kunnen de respons ook converteren naar strings tekst met de “.text” module. Omdat het decoderen van bytes naar een string een coderingsschema vereist zal requests proberen het coderingsschema te raden op basis van de headers van de respons. je kunt echter ook een expliciet coderingsschema opgeven door “.encoding” in te stellen voordat je “.text” opent:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl') request.encoding = 'utf-8' print(request.text) |
Het is fantastisch om te kunnen werken met statuscodes en body content. Maar wanneer je meer informatie nodig hebt zoals metagegevens over de response zelf dan is het zaak om de headers van de respons te bekijken.
Om de headers te bekijken kunnen we de “header” module gebruiken:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl') print(request.headers) |
Om een specifieke header te bekijken vragen we deze op uit de geretourneerde dictionary. Let op, deze module is niet case sensitive:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl') print(request.headers['Content-Type']) |
Om URL parameters mee te geven kunnen we deze handmatig achter de URL plakken of dynamisch via een dictionary specificeren en meegeven als URL parameter.
#! /usr/bin/python import requests parameters = { 'page': 2, 'count': 25} request = requests.get('https://jarnobaselier.nl', params=parameters) print(request.url) print ('\n') print(request.text) |

Tot op heden werkte we alleen met GET commando’s waarmee we responses kunnen opvangen en bevragen. Maar om zelf ook naar een pagina te kunnen versturen gebruiken we POST commando’s. Laten we een aantal parameters definiëren welke we als data kunnen posten. De parameters in onderstaande noemen we “username” en “password”. We gaan ervanuit dat de pagina waar we naartoe posten ook deze velden heeft. De veldnamen kun je achterhalen in de source code. Dit werkt als volgt.
#! /usr/bin/python import requests parameters = { 'username': 'jarno', 'password': 'baselier'} request = requests.post('https://jarnobaselier.nl', data=parameters) print(request.url) print ('\n') print(request.text) |
Hierboven gebruiken we een dictionary om de data door te sturen. Maar we kunnen ook een lijst met tuples gebruiken:
#! /usr/bin/python import requests parameters = [('username', 'jarno', 'password', 'baselier')] request = requests.post('https://jarnobaselier.nl', data=parameters) print(request.url) print ('\n') print(request.text) |
Als je echter JSON-gegevens moet verzenden, kunt u de json-parameter gebruiken. Wanneer je JSON-gegevens via json doorgeeft zal requests de gegevens serialiseren en de juiste Content-Type-header toevoegen.
#! /usr/bin/python import requests request = requests.post('https://jarnobaselier.nl', json={'username':'jarno', 'password':'baselier'}) json_response = request.json() json_response['data'] |
Hierboven hebben we een voorbeeld gemaakt van form-based authentication en hoe je ieder ander formulier kunt invullen met de “requests” POST methode. De PUT methode (requests.put) werkt op dezelfde manier. Wanneer we basic authentication willen doen kunnen we de authenticatiegegevens als volgt opgeven:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl', auth=('jarno', 'baselier') print(request.text) |
Om deze lijn uit te breiden met een timeout (om te voorkomen dat een script oneindig blijft hangen als er iets mis gaat) doen we het volgende:
#! /usr/bin/python import requests request = requests.get('https://jarnobaselier.nl', auth=('jarno', 'baselier', timeout=3) print(request.text) |
Tot nu toe hebben we alleen te maken gehad met API’s verzoeken op hoog niveau, zoals GET en POST. Deze functies zijn abstracties van wat er gebeurt wanneer je uw verzoeken indient. Ze verbergen bepaalde onderliggende implementatiedetails zoals hoe verbindingen worden beheerd. Onder deze abstracties bevindt zich een klasse genaamd “Session”. Als je de controle over hoe verzoeken gedaan worden wilt verfijnen of als je de prestaties van deze verzoeken wilt verbeteren kun je een sessie-instantie gebruiken. Sessies worden gebruikt om de parameters in alle aanvragen te behouden. Als je bijvoorbeeld dezelfde verificatie voor meerdere verzoeken wilt gebruiken kunt je een sessie gebruiken.
In onderstaande voorbeeld gebruiken we een sessie. Wat gebeurt er:
We importeren “getpass” zodat we het wachtwoord als userinput kunnen aangeven. Dan openen we een sessie met een username en een password welke we opgeven via de terminal. Vervolgens gebruiken we session.get om de URL op te geven waar we de sessie starten op basis van de hiervoor aangegeven waardes en tenslotte inspecteren we de reactie.
#! /usr/bin/python import requests from getpass import getpass with requests.Session() as session: session.auth = ('username', getpass()) response = session.get('https://jarnobaselier.nl/login') # You can inspect the response just like you did before print(response.headers) print(response.json()) |
Zoals je ziet is de requests library perfect voor het maken en interpreteren van verzoeken naar een webserver. Laten we nu eens naar een parser gaan kijken, namelijk “Beautiful Soup”
Beautiful Soup
Voorgaande “request” library maakt het gemakkelijk om informatie op te vragen en te posten… maar deze informatie kan niet geparsed worden. Beautiful Soup is een parser die dit wel kan. Beautiful Soup werkt bovenop een HTML/ XML en biedt Pythonische idiomen voor iteratie, zoeken en wijzigen van de parse-boom. Beautiful Soup is een toolkit voor het ontleden van een document en het extraheren van wat je nodig hebt. Met andere woorden, “scraping”. Beautiful Soup converteert automatisch inkomende documenten naar Unicode en uitgaande documenten naar UTF-8 zodat je zelf niet over encodering na hoeft te denken (tenzij het document geen codering specificeert en Beautiful Soup deze niet zelf kan detecteren). Daarnaast zit Beautiful Soup bovenop andere Python-parsers zoals lxml en html5lib zodat je verschillende parsing-strategieën kunt uitproberen of snelheid kunt uitwisselen voor flexibiliteit.
Installatie:
pip install beautifulsoup4 |
Voorbeelden:
Het eerste wat we gaan doen is het importeren van de library en het creeren van een “instance” van de Beautiful Soup class zodat we later het document kunnen parsen.
from bs4 import BeautifulSoup soup = BeautifulSoup(%variabele-requests-module%.content, 'html.parser') |
Nu gaan we deze samenvoegen met onze “requests” module. Met “requests” vragen we de content van een pagina op en deze gaan we parsen met Beautiful Soup. Tenslotten printen we de output met “Beautiful Soup” op een mooie / gestructureerde manier (prettify):
#! /usr/bin/python import requests from bs4 import BeautifulSoup request = requests.get('https://jarnobaselier.nl') soup = BeautifulSoup(request.content, 'html.parser') print(soup.prettify()) |

Zo kunnen we ook titels extraheren met de “soup.title” module. Wanneer je de titel wilt hebben zonder de HTML tags gebruik je de “text” parameter. Daarnaast kunnen we ook alle hyperlinks op de pagina extraheren door gebruik te maken van een loop. Bijvoorbeeld:
#! /usr/bin/python import requests from bs4 import BeautifulSoup url = 'https://jarnobaselier.nl' request = requests.get(url) soup = BeautifulSoup(request.content, 'html.parser') print(soup.title) print('\n') print(soup.title.text) print('\n') for link in soup.find_all("a"): print("Hyperlink tekst: {}".format(link.text)) print("Titel: {}".format(link.get("title"))) print("href: {}".format(link.get("href"))) print('\n') print('\n') print(soup.prettify()) |

Scapy
Scapy is een fantastische applicatie welke onze de controle geeft over de datapakketten welke we verzenden. Met Scapy kunnen we o.a. TCP en UDP pakketten maken en versturen. Maar met Scapy kunnen we ook pakketten onderscheppen en modificeren. Het is een uitgebreide tool waarin eveneens de basic tasks uitgevoerd kunnen worden. Scapy vervangt o.a. HPing, ArpSpoof. TCPDump, Wireshark en een groot gedeelte van NMap en voegt daar zijn eigen packet prototyping mogelijkheden aan toe. We hebben al eens vaker een post gedaan omtrent Scapy https://jarnobaselier.nl/scapy-network-packet-toolkit. Maar Scapy is ook volledig te gebruiken via Python. Fantastisch voor het automatiseren van sneller taken en packet prototyping. Laten we eens een paar voorbeeldjes bekijken.
Installatie:
pip install scapy |
Voorbeelden:
Een mooi voorbeeld is om een simpele sniffer te maken. Laten we de eerste 10 pakketten op de lijn eens sniffen en de output hiervan bekijken:
from scapy.all import * a=sniff(count=10) a.nsummary() |

Uiteraard zou je ditzelfde in een loop kunnen schrijven en elke keer wanneer er 10 packets gecaptured zijn de output tonen:
from scapy.all import * from os import system, name # define clear function def clear(): # for windows if name == 'nt': _ = system('cls') # for mac and linux(here, os.name is 'posix') else: _ = system('clear') while True: clear() a=sniff(count=10) a.nsummary() |
Voor het versturen wan pakketten moeten we een aantal extra zaken weten zoals de doelcomputer, het protocol en de actieve netwerkkaart. Om deze te achterhalen kunnen we b.v. “netifaces” gebruiken (weer een andere prachtige module). Maar in dit voorbeeld geven we de actieve NIC handmatig op. Vervolgens geven we 2 verzendmethodes op ter illustratie. De “send()” methode voor het versturen van pakketten op laag 3, en de “sendp()” methode voor het versturen van pakketten over laag 2.
from scapy.all import * Endpoint = '192.168.178.99' Protocol = ICMP TimeToLive = 1,4 ActiveInterface = 'Wi-Fi' #Verzend pakketten op Layer 3 send(IP(dst=Endpoint)/Protocol()) #Verzend pakketten op Layer 2 sendp(Ether()/IP(dst=Endpoint,ttl=(TimeToLive)), iface=ActiveInterface) |
Maar soms is het handig om zowel te kunnen verzenden als te kunnen “luisteren”. Hiervoor kent Scapy de “sr()” functie. Een afgeleide daarvan is de “sr1()” functie welke alleen luistert voor antwoord pakketten van reeds verzonden pakketten.
In onderstaande voorbeeld versturen we dus een ping en luisteren we meteen naar binnenkomende pakketten:
from scapy.all import * Endpoint = '8.8.8.8' Protocol = ICMP TimeToLive = 1,4 ActiveInterface = 'Wi-Fi' ans,unans=sr(IP(dst=Endpoint,ttl=TimeToLive)/Protocol()) ans.nsummary() |
Als resultaat kun je hier best hebben dat je 4 pakketten verzend maar 20 pakketten retour krijgt.
Vervolgens gebruiken we nu de “sr1()” optie om alleen de pakketten te ontvangen welke een antwoord zijn op de reeds verzonden pakketten. Ook gebruiken we de “.show” functie welke de details van het verzonden pakket laat zien.
from scapy.all import * Endpoint = '8.8.8.8' Protocol = ICMP TimeToLive = 1,4 ActiveInterface = 'Wi-Fi' p=sr1(IP(dst=Endpoint)/Protocol()/"XXXXXX") p.show() |

Om hetzelfde te doen op layer2 kun je de “srp()” en “srp1()” functies gebruiken.
Mocht je met Scapy een Python script maken en deze uitvoeren vanaf de CLI dan kun je gebruik maken van system arguments. Wanneer je b.v. onderstaande commando uitvoert wil je b.v. 8.8.8.8 meenemen naar je script en deze als endpoint waarde gebruiken.
python scapy-script.py 8.8.8.8 |
Dit doen we door gebruik te maken de sys library en om hiervan het “sys.argv” component te gebruiken. 8.8.8.8 is het eerste argument welke meegegeven wordt en dus ziet het vorige script er nu als volgt uit:
from scapy.all import * import sys Endpoint = sys.argv[1] Protocol = ICMP TimeToLive = 1,4 ActiveInterface = 'Wi-Fi' p=sr1(IP(dst=Endpoint)/Protocol()) p.show() |
Laten we eens goed kijken hoe we het pakket laag-voor-laag opbouwen te beginnen met de ethernet laag (2) en vervolgens het IP protocol (3) met daarin het TCP protocol. Lagen scheiden we zoals je al gezien had met de foreward slash (/) en multiple lines in Python met de backward slash (\).
from scapy.all import *
import sys
Endpoint = '8.8.8.8' EndpointPort = 80 Protocol = ICMP TimeToLive = 1,4 ActiveInterface = 'Wi-Fi' packet = Ether()/ \ IP(dst=Endpoint)/ \ TCP(dport=EndpointPort) packet.show() |
Door op die manier pakketten op de bouwen kun je zelf alle waardes binnen een pakket bepalen:
from scapy.all import * Endpoint = '8.8.8.8' EndpointPort = 80 Protocol = ICMP TimeToLive = 1,4 ActiveInterface = 'Wi-Fi' packet = \ Ether(dst='c2:8a:ed:09:21:5a') / \ IP(dst=Endpoint, id=4, ttl=128) / \ TCP(sport=9000, dport=EndpointPort, ack=1) packet.show() send(packet) |
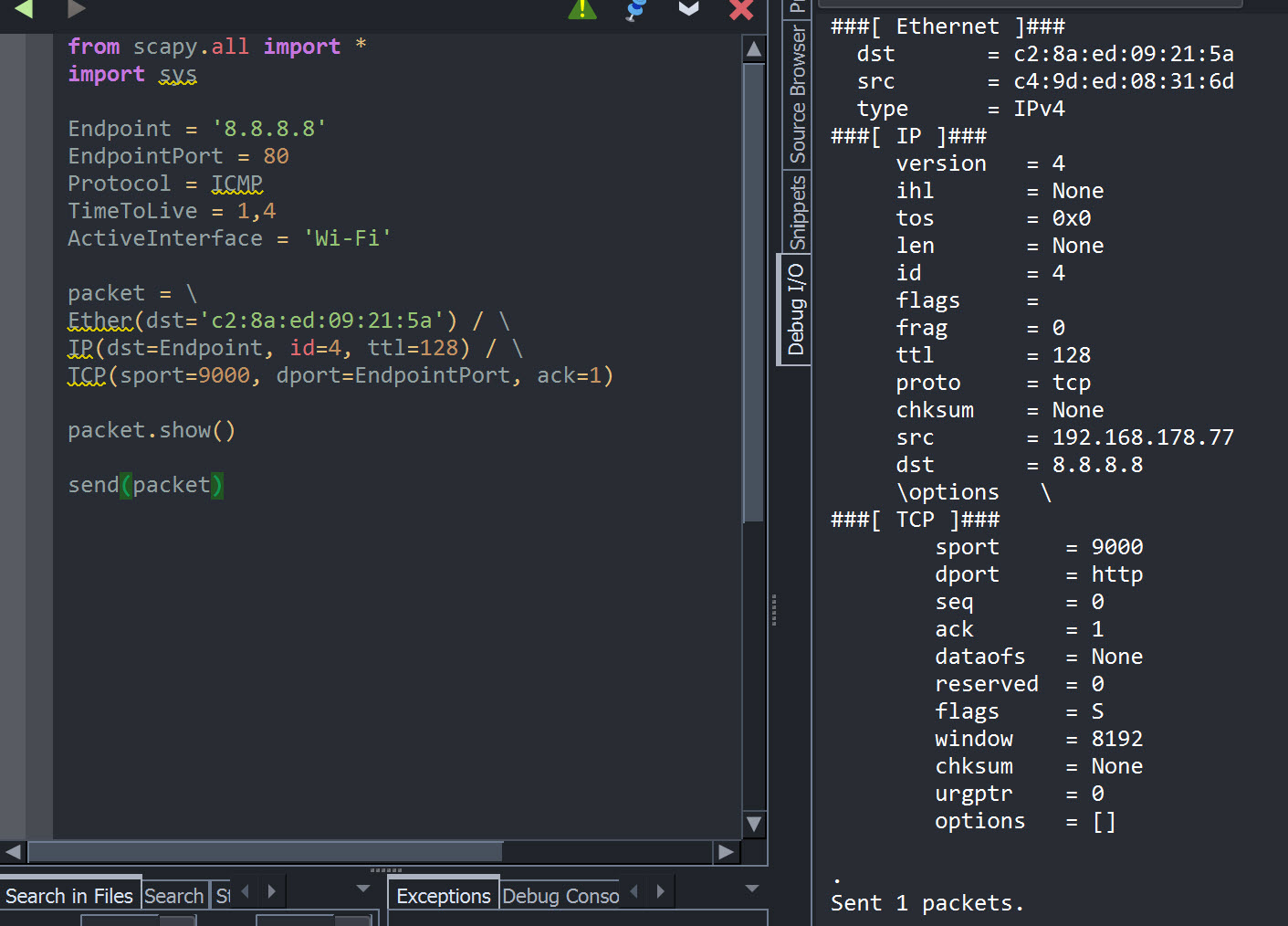
Dat is de Python Scapy implementatie in een notendop. Een zeer krachtige library met een ton aan potentie!
Sockets
De sockets library maakt het mogelijk om simpele servers en clients op te zetten met Python waarmee je kunt communiceren met sockets. Een socket kun je zien als een endpoint bij de communicatie tussen applicaties op een netwerk. Sockets zijn meestal verbonden aan een poort op de host.
Installatie:
Sockets is in principe een standaard module. Mocht je hem toch moeten installeren dan doe je dat als volgt:
pip install sockets |
Voorbeelden:
Laten we eens beginnen met een simpel voorbeeld. Laten we eens een listener opzetten:
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind((socket.gethostname(), 8888)) s.listen(5) while True: clientsocket, address = s.accept() print(f"De verbinding v.a. {address} is succesvol. {address} is nu verbonden.") clientsocket.send(bytes("Hallo","utf-8")) |
Allereerst reserveren we een socket op basis van IPv4 (AF.INET) en TCP (SOCK_STREAM). Dan maken we een bind op de huidige hostnaam met poortnummer 8888. Dan gaan we luisteren voor inkomende verbindingen op deze host op poort 8888 en we zorgen ervoor dat er een queue is van maximaal 5 verbindingen (overige worden gedenied). De while loop blijft loopen en zorgt ervoor dat er continue geluisterd wordt. Wanneer er een verbinding gemaakt wordt zorgt de loop ervoor dat de verbinding wordt geaccepteerd (s.accept) en dat het client adres wordt opgeslagen in de address variabele. Daarna wordt er een string getoond met de tekst dat er een succesvolle verbinding is gemaakt en vervolgens stuurt de server een bericht (Hallo) naar de client.
Wanneer we nu een client willen maken die gaat verbinden op deze listener dan doen we het anders. We reserveren weer een socket op basis van IPv4 (AF.INET) en TCP (SOCK_STREAM) om UDP te gebruiken zou je SOCK_DGRAM (datagram) kunnen gebruiken. Vervolgens connecten we naar de localhost (zelfde hostname als server als deze op dezelfde client wordt uitgevoerd) op poort 8888.
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((socket.gethostname(), 8888)) |
Wanneer we niet zouden verbinden naar de localhost maar naar een extern IP adres dan zou dit er als volgt uitzien:
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) publicip = '131.21.140.10' s.connect((publicip, 8888)) |
Op dit moment ontvangt de client nog niet het “Hallo” bericht van de server. De socket luistert nog niet voor data. Laten we een receive buffer toevoegen van 1024 bytes (per keer). Vervolgens laten we de ontvangen tekst zien door deze te “printen”:
import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) publicip = '131.21.140.10' s.connect((publicip, 8888)) msg = s.recv(1024) print(msg.decode("utf-8")) |
Bovenstaande kan uitgebreider (wat te doen als een socket hangt en wederzijdse communicatie) en kan ook efficiënter. Maar dit is de basis van de sockets Python module. Handig om communicatie tussen 2 endpoint over TCP of UDP op te zetten!
PwnTools is een Python based CTF (Capture the Flag) toolkit en verdient eigenlijk ook zijn eigen post. PwnTools is geschreven voor snelle prototyping en development en bedoeld om het schrijven van exploits zo eenvoudig mogelijk te maken. Of je PwnTools nu gebruikt om exploits te schrijven of als onderdeel van een ander softwareproject, het is aan jou om te kijken hoe je het gebruikt. Vroeger werd PwnTools gebruikt als een soort exploit schrijvende DSL. V.a. PwnTools v2 bestaat PwnTools uit 2 modules, namelijk: PwnLib (nette, schone Python-module) en Pwn (welke speciaal voor CTF’s gebruikt zou worden). Voor dit voorbeeld richten we ons op de Pwn module. Deze kunnen we gebruiken voor allerhande doeleinden zoals het creëren van buffer overflows, het schrijven van shellcode, en het praten met sockets en processen.
Installatie:
pip install pwntools |
Voorbeelden:
Om de Pwn module te kunnen gebruiken specificeer je deze. Door alle functionaliteit te importeren krijg je toegang tot een breed scala aan functie. Welke? Nou deze http://docs.pwntools.com/en/stable/globals.html:
from pwn import * |
Zo zijn er verschillende “tubes” om interactie te krijgen met processen, seriële poorten, sockets en SSH. De log functie zorgt ervoor dat je mooie logs kunt maken. Util.cyclic geeft je toegang tot applicaties voor het maken van strings, shellcraft voor het genereren van shellcode en ELF voor de manipulatie van binaries. En zo zijn er nog heel veel meer. Laten we dus even een paar voorbeelden bekijken.
Laten we eens een verbinding opzetten middels pwntools.tubes module.
from pwn import * #Creer een socket: conn = remote('ftp.jarnobaselier.nl',21) #Ontvang de receive line als een string conn.recvline() #Verstuur de username conn.send('USER anonymous\r\n') #Ontvang data tot de opgegeven string leeg ontvangen is conn.recvuntil(' ', drop=True) #Ontvang de receive line als een string conn.recvline() #sluit de verbinding conn.close() |
Om een SSH connectie op te zetten we een SSH Connector op. Dit doen we als volgt:
from pwn import * l = listen() s = ssh(host='jarnobaselier.nl', user='jarno', password='baselier') a = s.connect_remote(s.host, l.lport) b = l.wait_for_connection() a.sendline('Hello') print repr(b.recvline()) |
Om een listener op te zetten kun je het volgende gebruiken:
from pwn import * l = listen(9999) r = remote('localhost', 9999) svr = l.wait_for_connection() r.send('hello') print svr.recv() |
In bovenstaande voorbeeld zetten we een listener (l) op en vervolgens een client (r). Vervolgens wordt de verbinding gemaakt.
Met tubes.process wordt er een nieuw proces gestart en gewrapt in een “tube” zodat je ermee kunt communiceren. Wanneer het proces is gestart heb je een breed scala aan commando’s om te kunnen communiceren zoals
from pwn import * p = process('cmd') p.sendline(b"print 'shutdown -r -t 0'") |
Hierboven starten we de Windows command-prompt en vervolgens voeren we hier het commando in om de computer te rebooten.
Wanneer je uitvoerbare binaire (Linux) bestanden hebt dan zijn dit meestal ELF files (Executable and Linking Format). Deze kun je debuggen in een debugger of met PwnTools de gewenste informatie opzoeken tijdens het draaien van het ELF bestand.
Hieroner laten we zien hoe we de geheugenadressen kunnen vinden van een ELF bestand:
from pwn import * e = ELF('/bin/cat') #Lees het start adres print(hex(e.address)) #Maak een dictionary met alle name->address waardes van het ELF bestand print(hex(e.symbols['write'])) #Maak een dictionary aan met alle adressen van de global offset tables print(hex(e.got['write'])) |
Laten we een binary file aanpassen en opslaan:
from pwn import * #Originele ELF bestand (CAT) e = ELF('/bin/cat') #Lees de eerste 3 bytes van het ELF bestand e.read(e.address+1, 3) #Modificeer (assemble) deze bytes voor de string waarde “ret” e.asm(e.address, 'ret') #Sla de binary op als “quiet-cat” in de temp directory e.save('/tmp/quiet-cat') #Disassemble quiet-cat en lees de eerste byte om het resultaat te bekijken disasm(open('/tmp/quiet-cat','rb').read(1)) |
En zo zijn er nog honderden voorbeelden die we kunnen geven van de PwnTools library. Deze library verdient meerdere unieke posts om de volledige potentie te kunnen tonen. Je bent dus ook wel een
MechanicalSoup
MechanicalSoup is een afgeleide van Beautiful Soup en Mechanize. Mechanize was gebouwd bovenop de urllib2 library en MechanicalSoup is gebouwd bovenop de “Requests” library. MechanicalSoup is een zogenaamde “stateful programmatic web browser”. Browserobjecten hebben een status, inclusief navigatiegeschiedenis, HTML-formulierstatus, cookies, enz. Deze functiesets en URL-schema’s zijn configureerbaar. MechanicalSoup kent diverse functies waaronder FTP, HTTP, URL Schema’s, Browsergeschiedenis, Hyperlinks, Formulieren, Cookies, Proxies, Authenticatie (basic & digest) etc. MechanicalSoup kan o.a. gebruikt worden als auto-form-filler of als hyperlink clicker. Daarnaast kan data gescraped worden zoals we al eerder hebben gezien. Java wordt echter niet ondersteund. MechanicalSoup is een prachtige mengeling van bovenstaande modules en een zeer krachtige op zichzelf staande module welke actief onderhouden wordt en in tegenstelling tot Mechanize compatible is met Python 3.
Installatie:
De installatie is net als die van de overige libraries net zo simpel met Pip:
pip install MechanicalSoup |
Voorbeelden:
Ook MechanicalSoup kent een breed scala aan opties en mogelijkheden. Hieronder een kleine introductie:
Laten we eens een instantie maken welke de opgegeven pagina opent in een “echter” browser:
<pre lang="bash"> import mechanicalsoup #Start Browser browser = mechanicalsoup.StatefulBrowser() #Open Website browser.open("https://jarnobaselier.nl") browser.launch_browser() |
We kunnen ook de paginatitel en de paginacontent weergeven:
import mechanicalsoup #Start Browser browser = mechanicalsoup.StatefulBrowser() #Open Website browser.open("https://jarnobaselier.nl") print(browser.get_url()) print("\n") print(browser.get_current_page()) |

Uiteraard kunnen we ook specifieke dingen doen zoals het oproepen van alle URL’s op de pagina:
import mechanicalsoup #Start Browser browser = mechanicalsoup.StatefulBrowser() #Open Website browser.open("https://jarnobaselier.nl") #Find UL’s browser.get_current_page().find_all('ul') |
Of een link volgen:
import mechanicalsoup #Start Browser browser = mechanicalsoup.StatefulBrowser() #Open Website browser.open("https://jarnobaselier.nl") #Follow Link browser.follow_link("over-jarno-baselier") #Show result print(browser.get_url()) print("\n") print(browser.get_current_page()) |

Het is ook mogelijk om andere aspecten te beïnvloeden zoals formulieren. De volgende code vult het “lid worden van nieuwsbrief” op mijn pagina in:
import mechanicalsoup #Start Browser browser = mechanicalsoup.StatefulBrowser() #Open Website browser.open("https://www.jarnobaselier.nl") # Fill-in the Jarno Baselier newsletter form browser.select_form('form[action="/"]') browser["input_3"] = "Jarno" browser["input_4"] = "Baselier" browser["input_2"] = "ditisniet@mijnmail.nl" # Note: the button name is btnK in the content served to actual # browsers, but btnG for bots. browser.submit_selected(btnName="gform_submit_button_1") page = browser.page print(page.title.text) |
Het volgende script gebruikt regulaire expressies om alle hyperlinks van een Google zoekresultaat (van pagina 1) te tonen:
import re import mechanicalsoup #Start Browser browser = mechanicalsoup.StatefulBrowser() #Open Website browser.open("https://www.google.com/") # Fill-in the form met Jarno Baselier browser.select_form('form[action="/search"]') browser["q"] = "Jarno Baselier" # Note: the button name is btnK in the content served to actual # browsers, but btnG for bots. browser.submit_selected(btnName="btnG") # Display all hyperlinks for link in browser.links(): target = link.attrs['href'] # Filter-out unrelated links and extract actual URL from Google's # click-tracking. if (target.startswith('/url?') and not target.startswith("/url?q=http://webcache.googleusercontent.com")): target = re.sub(r"^/url\?q=([^&]*)&.*", r"\1", target) print(target) |
Conclusie
Bovenstaande kennis zou b.v. erg handig kunnen zijn bij een capture the flag. Neem als voorbeeld een timing attack in combinatie met een sessionkey parameter. Bij een succesvolle parameter is de resolvement tijd een stuk langer. Door deze procedure als volgt te scripten kun je gemakkelijk verschillende keys proberen en aan de hand van de tijd zien welke keys succesvol zijn.
#! /usr/bin/python import requests import time url = "https://jarnobaselier.nl" user_agent = "Chrome/83.0.4103.116 Safari/537.36" headers = { "User-Agent": user_agent } counter = 0 while counter < 1001: url_parameters = { "sessionKey": "counter", "format": "xml" } start = time.time() r = requests.get(url, headers = headers, params = url_parameters) end = time.time() deltatime = end-start print("Trying different session keys- current key = ", counter, ". The duration was:", deltatime) if deltatime < 4.5: #Wrong SessionKey counter = counter + 1 continue else: print("This might be the right sessionkey \n ", counter) break |
Wat mij betreft blijven “Requests” en “Scapy” eigenlijk in de meeste gevallen de allerbelangrijkste Python libraries. Maar de overige libraries voegen echter weer eigen functionele krachten toe en zoals altijd is het dus maar net wat je nodig hebt. Wil je scripten like a boss kies dan de libraries die voor jou het meest van toepassing zijn en probeer de functionaliteiten zo vaak mogelijk te benutten. Op die manier bouw je steeds betere en veelzijdigere scripts. Er zijn nog zoveel andere libraries die ik had willen laten zien… maar deze behoren in ieder geval tot mijn “netwerk favorieten”!
Hopelijk heb je genoten van deze post en heb je misschien zelfs nog wat tips of inspiratie opgedaan. Ik hoop in ieder geval dat je hem leuk vond om te lezen en ik zou het fantastisch vinden om dat te “horen”! Stuur een leuk bericht, like deze post of deel hem op je eigen website of social media. Dit soort posts maken kost veel tijd dus elke waardering is welkom! ❤ Je bent een TOPPER ❤!