





Encoding en Charsets – Hoe zit dat
Als je met computers, devices, software en scripts werkt dan kom je vaak de term “encoding” tegen. Formaten (indelingen) als UTF, ASCII, Unicode en ANSI zijn veelvoorkomende standaarden maar zijn niet allemaal encoding schema’s. Deze standaarden hebben ook weer verschillende varianten. Zo heeft UTF ook UTF-8, UTF-16 en zelfs UTF-7 en 32 varianten. ASCII en UTF zijn encoding varianten maar Unicode en ANSI noemen we ook wel “CharSets” (karakter sets) ofwel “repertoire’s”. Een karakterset is een mapping tussen een bit (want zo slaat een computer data op) en een letter op het beeldscherm. Verwarrend? Meer weten… stop dan niet met lezen!
Zoals we hierboven al vermeld hebben is het eerst zaak om te weten wat een CharSet en wat een “Encoding Schema” is. Als je op het toetsenbord een toets intikt komen er letters op het beeldscherm. Deze informatie wordt ergens vandaan gehaald. De computer slaat namelijk geen “letters” op. Deze werkt met bits. Een bit kan 2 waardes hebben zoals “1” of “0”. De “1” zal ik sommige gevallen staan voor “Yes” en vervolgens zal de “0” dan “No” representeren. Deze 1en en 0en noemen we “binary code” en is afkomstig uit elektrische signalen die dus “AAN = 1” en “UIT = 0” konden zijn. Maar als we alleen maar 1en en 0en op het beeldscherm konden zien dan zou het allemaal wat minder interessant zijn en zou YouTube niet bestaan. Om dus “iets” op het beeldscherm te tonen bestaan er heel veel regels. Ook voor het tonen van letters hebben we regels verzonnen. Een combinatie van bits kan volgens een bepaalde regel een letter representeren. Bijvoorbeeld:
01001010 01100001 01110010 01101110 01101111
De binary code hierboven spelt het woord “Jarno”. Elk setje van 8 bits (een byte) representeert een letter. Welke letter deze binaire code representeert is afhankelijk van het schema dat voor de vertaling gebruikt wordt. Het gebruikte schema noemen we een “charset”. Een charset geeft dus aan welke symbolen we kunnen gebruiken. Hoe we deze code vervolgens opslaan in het geheugen wordt bepaald door het “encoding schema”. De ASCII codering is simpelweg de methode hoe de karkaters in het geheugen worden opgeslagen. Dit noemen we dan ook een “encoding schema”.
Een toets op het toetsenbord wordt omgezet naar een binaire, octale of hexadecimale code welke wordt opgeslagen in het geheugen. Hoe deze wordt opgeslagen is afhankelijk van het encoding schema zoals ASCII. Als we later het symbool op het beeldscherm willen tonen moet deze binaire, octale of hexadecimale code weer omgezet worden naar een “symbool”. Dit omzetten doen we middels een specifieke “charset”.
Hieronder zien we de ASCII encoding. De eerste letters in het ASCII schema zien er als volgt uit:
01000001 = A
01000010 = B
01000011 = C
01000100 = D
01000101 = E
01000110 = F
01000111 = G
Als we op het toetsenbord de G intypen dan wordt deze bij een ASCII encoding opgeslagen in het geheugen als “01000111”. Om deze op het scherm te tonen wordt een charset gebruikt. Als UTF-8 wordt gebruikt dan wordt “\x47” volgens de omzettingstabel omgezet naar “G”. Maar “47” is toch iets heel anders dan “01000111”? Klopt. 47 is een hexadecimale waarde welke weer gelijk staat aan “01000111”. Maar hierover later meer.
Belangrijk om te weten is dat:
Encoding Schema: Op deze manier worden karakters in het geheugen opgeslagen.
Charset: Op deze manier worden gegevens vanuit het geheugen omgezet naar symbolen.
In het ASCII schema kent 95 leesbare karakters. Dit zijn zowel alle kleine letters, hoofdletters de cijfers en diverse leestekens. Daarnaast zijn er nog 33 ASCII tekens voor tekstinterpretatie zoals spaties, tabs, backspace en codes die alleen voor een computer handig zijn zoals de aanduiding voor het begin en het einde van een regel. In het totaal kent ASCII dus 128 tekens en worden alle combinaties van 7 bits (0000000 tot 1111111) gebruikt.
Bovenstaande ASCII encoding maakt het mogelijk om invoer om te zetten naar binaire nummers. Deze nummers kunnen echter ook op andere manieren opgeslagen worden in het geheugen. Denk aan bijvoorbeeld hexadecimaal en octaal. Hexadecimaal is doorgaans makkelijker te lezen dan binaire data en is ook korter. Bij decimale cijfers werken we met het grondgetal 10. Bij het octale stelsel werken we met het grondgetal 8 en bij het hexadecimale stelsel werken we met het grondgetal 16. Het octale stelsel is in de beginjaren van de computer veel gebruikt om binaire gegevens overzichtelijk weer te geven. Bij het octale stelsel hebben we de beschikking over de cijfers 0-7. Bij het hexadecimale stelsel hebben we de beschikking over de cijfers 1-9 + A-F.
Laten we eens kijken:
Decimaal: 1
Octaal: 1
Hexadecimaal: 1
Binair: 00000001
Decimaal: 7
Octaal: 7
Hexadecimaal: 7
Binair: 0000111
Decimaal: 8
Octaal: 10 (de 8 bestaat niet in het octale stelsel en dus gaan we naar de volgende stap die we kunnen maken, namelijk de 10).
Hexadecimaal: 8
Binair: 0001000
Decimaal: 9
Octaal: 11
Hexadecimaal: 9
Binair: 0001001
Decimaal: 10
Octaal: 12
Hexadecimaal: A (na de 9 komt de A)
Binair: 0001010
Decimaal: 16
Octaal: 20
Hexadecimaal: 10 (Na de F gaan we verder met 10, 11, 12 etc.)
Binair: 00010000
Decimaal: 32
Octaal: 40
Hexadecimaal: 20
Binair: 00100000
Decimaal: 42
Octaal: 52
Hexadecimaal: 2A
Binair: 00101010
De encoding tabel voor deze waardes ziet er als volgt uit:
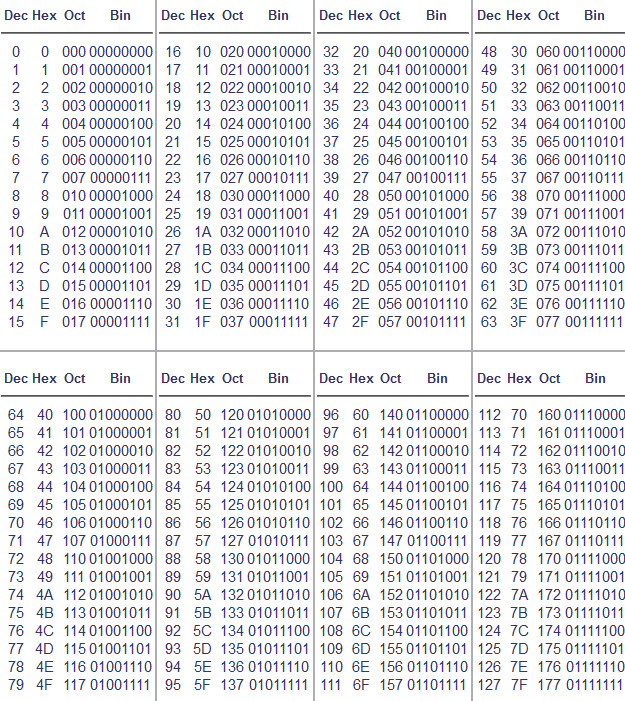
Als we echter nu gaan kijken naar taal, dan zijn de 95 karakters die we beschikbaar hebben in de ASCII tabel nooit voldoende. Denk eens aan alle “vreemde” letters en leestekens de buitenlande talen kennen. ASCII gebruikt echter maar 7 van de 8 beschikbare bits. Er is dus 1 bit over waar 128 extra tekens mee gemaakt kunnen worden. Met deze extra plaatsen zijn diverse setjes gemaakt. Een voorbeeld hiervan is ANSI ofwel Windows-1252. ANSI gebruikt de overige 128 plaatsen voor veelgebruikte Windows symbolen zoals diakritische symbolen. ANSI wordt gebruikt sinds Windows95 en is een tekenverzameling die de meeste symbolen bevat van de plaatsen waar op dat moment Windows 95 het meeste gebruikt wordt. In Noord-Amerika en West-Europa is dit set CP1252 welke voor het grootste gedeelte overeenkomt met de tekenset ISO 8859-1.
Maar 128 extra karakters is nooit voldoende om alle karakters uit alle talen in te kunnen verwerken (Hebreeuws, Chinees, Grieks, Russisch etc.). Het is juist om deze reden dat er zoveel verschillende soorten encoding schema’s bestaan. Schema’s bedoeld voor een specifieke taal, of voor meerdere talen. Zo kennen we verschillende ISO encodings. ISO 8859-6 voor Arabisch, ISO 8859-11 voor Thais en ISO 8859-1 voor West Europa.
Om dit probleem te tackelen heeft men bedacht om 2x een reeks van 8 bits te gebruiken. Dus 2 bytes voor 1 symbool / letter. Met 2 bytes, 16 bits zijn er ineens 65536 verschillende mogelijkheden i.p.v. de 256 mogelijkheden met 8 bits. Twee van de tabellen die “double-byte encoding” gebruiken zijn de “BIG-5” en de “GB18030” welke o.a. traditionele Chinese karakters bevatten. Maar ook deze double-byte encoding schema’s bevatten niet alle karakters.
Toen kwamen een aantal organisatie op het idee om een overzicht te maken waarbij iedereen geholpen zou zijn. “1 code tabel to rule them all”. Dit is wat “Unicode” is. Unicode bestaat sinds 1991 en is een internationale standaard voor de codering van grafische tekens. In die zin lijkt Unicode op de ASCII standaard. Maar Unicode is geen “encoding”.
Verwarrend toch?
Unicode is een charset en representeert dus een “codepoint” voor bepaald karakter. Codepoint “0047” staat bijvoorbeeld voor de “G” en “0048” staat voor de H. De standaard voorziet alle tekens van alle geschreven talen van een naam (in de standaard in hoofdletters geschreven) en een nummer (vaak hexadecimaal geschreven, voorafgegaan door U+). Zie hieronder:
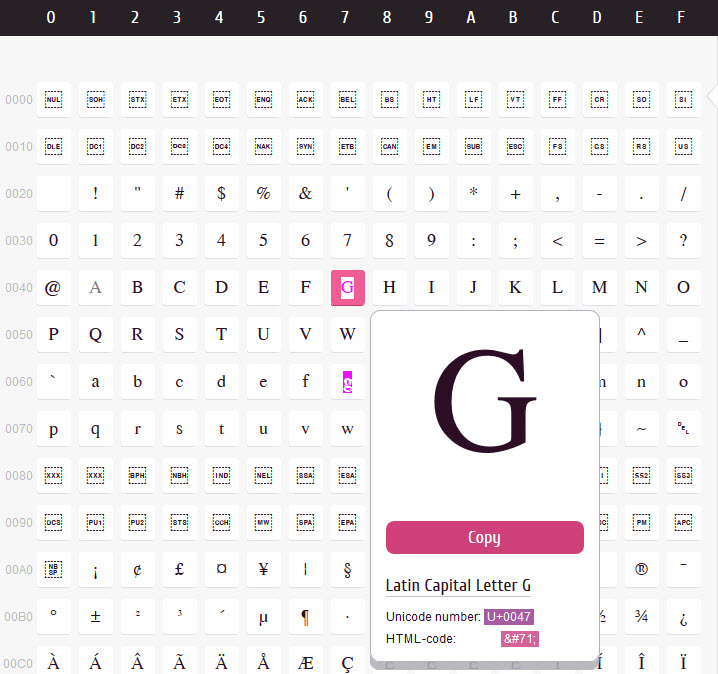
Hoe deze codepoints naar bits zijn gecodeerd is wat ingewikkelder. Unicode kent namelijk 1,114,112 mogelijke waarden. De Unicode 2 standaard kent ruim 100.000 gestandaardiseerde tekens en ongeveer 900.000 gereserveerde codes voor toekomstig gebruik. Unicode stelt geen beperkingen aan het aantal talen dat in één enkel document gebruikt kan worden. Naast letters en cijfers bevat Unicode ook veel symbolen, zoals: kruisen, wiskundige tekens, muntsymbolen enzovoort. Unicode bevat geen symbolen die niet in een schrift worden gebruikt, zoals verkeersborden.
Om zoveel waardes te representeren zijn twee bytes niet genoeg. Drie bytes kunnen voldoende zijn maar drie bytes zijn vaak lastig om mee te werken. Logisch is dus dat vier bytes het minimum zijn. Maar als we voor elke vertaling 4 bytes zouden gebruiken dan zou een tekstbestand ook 4x zo groot worden. En dat is zonder omdat je het gros van de Unicode tabel helemaal nooit gebruikt. Om dit te optimaliseren bestaan er verschillende manieren om Unicode-codepunten in bits te coderen. UTF (Unicode Transformation Format) is zo’n encoding schema. UTF is een encoding met variabele lengte waarbij niet ieder teken evenveel bytes gebruikt.
UTF-32 is zo’n codering die alle Unicode-codepunten codeert met behulp van 32 bits. Dat wil zeggen vier bytes per teken. UTF-32 bestanden zijn dus vaak groot omdat er veel ruimte verspild wordt. UTF-16 en UTF-8 zijn coderingen met variabele lengte. Als een teken kan worden weergegeven met behulp van een enkele byte (zoals het vastleggen van de 128 ASCII tekens), codeert UTF-8 het teken met een enkele byte. Als er twee bytes nodig zijn, worden er twee bytes gebruikt enzovoort. UTF-16 bevindt zich in het midden en gebruikt ten minste twee bytes, waar nodig tot maximaal vier bytes.
Zie hieronder een conversievoorbeeld van UTF:
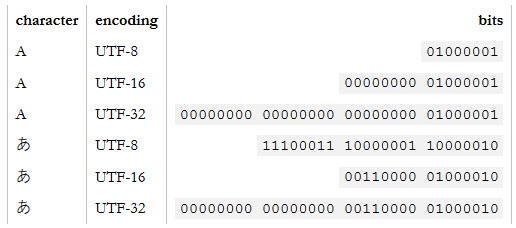
Het ingenieuze aan UTF-8 is dat het binair compatibel is met ASCII, wat meestal de basis is voor alle coderingen. Alle tekens die beschikbaar zijn in de ASCII-codering nemen slechts één byte op in UTF-8 en het zijn exact dezelfde bytes als die worden gebruikt in ASCII. Met andere woorden, ASCII wijst 1: 1 toe tot UTF-8. Elk teken niet in ASCII neemt twee of meer bytes op in UTF-8. Voor de meeste programmeertalen die verwachten ASCII te parsen, betekent dit dat u UTF-8-tekst rechtstreeks in uw programma’s kunt opnemen.
Encoding Resume
Ok. Laten we eens snel door de 4 “encodings” lopen die we aan het begin van deze post hebben vermeld, namelijk”: UTF, ASCII, Unicode en ANSI. Nu weten we hoe we deze standaarden moeten bekijken en interpreteren:
ASCII – American Standard Code for Information Interchange
Soort: encoding
Sinds: 1950
Aantal bits: 7 (met extended ASCII tot 8)
“Jarno” in ASCII Decimaal: 74 97 114 110 111
“Jarno” in ASCII Binary: 01001010 01100001 01110010 01101110 01101111
“Jarno” in ASCII Hex: 4A 61 72 6E 6F
UTF – Unicode Transformation Format
Soort: encoding
Sinds: 1993
Aantal bits: 8-32
“Jarno” in UTF-8 Hex: \x4a\x61\x72\x6e\x6f
“Jarno” in UTF-16 Hex: \u004a\u0061\u0072\u006e\u006f
“Jarno” in UTF-32 Hex: 0000004a00000061000000720000006e0000006f
Unicode
Soort: charset
Sinds: 1991
Aantal bits: Afhankelijk van de gebruikte encoding
ANSI – American National Standards Institute
Soort: charset
Sinds: 1979
Aantal bits: Afhankelijk van de gebruikte encoding
Fonts
Nu we bekend zijn met bovenstaande kunnen we ons de vraag stellen, hoe zit het dan met fonts? Er zijn heel veel verschillende fonts en de letterstyle staat echt niet gedefinieerd in het charset.
Een lettertype is een verzameling glyph-definities ofwel definities van de stijl die wordt gebruikt om karakters weer te geven.
Zodra computer heeft vastgesteld met welke tekens het te maken heeft, zoekt het in het lettertype naar glyphs die het kan gebruiken om die karakters weer te geven in de style die het lettertype representeert. Als in dit geval de encoding informatie fout is zoekt de computer naar een glyphs voor de verkeerde tekens. Een bepaald lettertype dekt meestal een enkele tekenset of, in het geval van een grote tekenset als Unicode, slechts een subset van alle tekens in de set. Als het lettertype geen glyph/style heeft voor een bepaald teken, zullen sommige browsers of softwaretoepassingen zoeken naar de ontbrekende glyphs in andere lettertypen op het system. Dit resulteert vaak in het fenomeen dat de glyph er anders uitziet dan de omringende tekst. Vaak ziet dit er dan uit als een vierkant, een vraagteken of een ander teken.
Conclusie
In essentie is het dus niet zo moeilijk en ingewikkeld als het allemaal lijkt. Op het moment dat je een teken aanraakt op je toetsenbord wordt deze opgeslagen in het geheugen als een bepaalde waarde (hexadecimaal of binair) opgeslagen. Hoe, dat bepaald het gebruikte encoding schema zoals ASCII of UTF. Het teken dat getoond wordt is het symbool dat opgezocht wordt in een charset en overeen komt met de opgeslagen waarde. Hoe het karakter er exact uitziet wordt bepaald door het gebruikte font. Het font vormt het karakter met zijn eigen glyph zodat het een eigen stijl krijgt.
Vond je deze post leuk, geef dan een leuke reactie, like en deel deze post (of mijn website) op je sociale media of eigen website. Het maken van dit soort posts kost veel tijd en leuke (re)acties zorgen ervoor dat ik met veel plezier blijf schrijven. Heel erg bedankt!