





Buffer Overflow
In deze post ga ik het hebben over een belangrijke “hacker” techniek waar ik het nog nooit eerder over gehad heb, namelijk “Buffer Overflows”. Waarom ik het nog nooit over buffer overflows gehad heb heeft meerdere redenen. Allereerst is het een techniek die je als pentester vrijwel nooit toepast. Een buffer overflow resulteert namelijk vaak in een DOS (Denial of Service) aanval en dat is precies wat je vaak niet wilt hebben. Daarnaast vind ik het ook lastig uit te leggen. Er zijn namelijk vele variabelen die een buffer overflow kunnen veroorzaken. Een buffer overflow is geen straightforeward proces. Daarom gaan we in deze post de basis van een buffer overflow bekijken. Als de basis duidelijk is dan zou je de techniek toe kunnen passen maar hou er rekening mee dat een buffer overflow veel maatwerk en testen vereist omdat elke situatie anders is.
Een buffer overflow. Wat is dat dan? Buffer… klinkt als iets met het geheugen toch? Klopt. Een buffer overflow heeft altijd iets te maken met het RAM geheugen van een computer. Een buffer overflow noemen we ook weleens een “buffer overrun”. Een buffer overflow is een aanval op het geheugen waarbij een programma tijdens het schrijven van gegevens naar een buffer, de buffergrens overschrijdt en aangrenzende geheugenlocaties overschrijft. Door dit te doen kan informatie benaderd worden welke eigenlijk niet toegankelijk mocht zijn voor de gebruiker.
Omdat een buffer overflow zoveel te maken heeft met “het geheugen” is het belangrijk om te weten hoe dit geheugen (meestal) is opgebouwd en wat hierin omgaat. Het geheugen waar we het over hebben is niet de opslagcapaciteit (de harde schijf) maar het RAM geheugen. RAM staat voor “Random access memory” en is de bekendste vorm van computergeheugen. RAM wordt beschouwd als “random access” omdat je rechtstreeks toegang hebt tot elke geheugencel als je de rij en de kolom kent die elkaar kruisen in een cel.
Het tegenovergestelde van RAM geheugen is SAM geheugen. SAM staat voor “Serial Access Memory” en slaat gegevens op als een reeks geheugencellen die alleen sequentieel toegankelijk zijn (zoals een cassettebandje). Als gegevens zich niet op de huidige locatie bevinden, wordt elke geheugencel gecontroleerd totdat de benodigde gegevens zijn gevonden. SAM werkt erg goed voor geheugenbuffers waar de gegevens normaal gesproken worden opgeslagen in de volgorde waarin ze zullen worden gebruikt (een goed voorbeeld is het textuurbuffergeheugen op een videokaart). RAM-gegevens zijn daarentegen in elke volgorde toegankelijk. In deze post spitsen we ons toe op RAM geheugen.
Net als bij een microprocessor is een RAM geheugenchip een geïntegreerd circuit (IC) gemaakt van miljoenen transistors en condensatoren. In de meest voorkomende vorm van RAM geheugen DRAM (Dynamic Random Access Memory) Bij DRAM worden een transistor en een condensator gekoppeld om een geheugencel te creëren die een enkel bit aan gegevens vertegenwoordigt. De condensator bevat het stukje informatie – een 0 of een 1. De transistor fungeert als een schakelaar waarmee het regelcircuit op de geheugenchip de condensator kan lezen of de status ervan kan veranderen.
Zie een condensator is als een emmer die elektronen kan opslaan. Om een 1 in de geheugencel op te slaan, is de condenstator gevuld met elektronen. Om een 0 op te slaan wordt de condensator leeg gemaakt. Het probleem met condensatoren is dat deze allemaal lek zijn., Dit betekend dat een “volle emmer” binnen een paar milliseconden weer leeg is. Dus om dynamisch geheugen te kunnen laten werken moet geheugencontroller (CPU) alle condensatoren opladen die een 1 vasthouden (de emmer weer bijvullen) voordat ze ontladen. Om dit te doen leest de geheugencontroller het geheugen en schrijft het vervolgens meteen terug. Deze vernieuwingsbewerking gebeurt automatisch duizenden keren per seconde. Omdat deze “vernieuwingsprocedure” bestaat noemen we het DRAM. DRAM heeft echter als nadeel dat deze verfrissingen ook tijd kost en het geheugen vertraagt. Het “rechargen” of activeren van een cel wordt uitgedrukt in nanoseconden (miljardste van een seconde). Een geheugenchip met een snelheid van 70ns doet er 70 nanoseconde over om de cel te legen en weer opnieuw te vullen. Nu weet je ook exact waarom al het RAM geheugen verloren gaar als de computer uitgeschakeld wordt. Zorg er bij forensisch onderzoek altijd voor dat devices ingeschakeld blijven zodat je het overgebleven deel van het geheugen kunt dumpen en analyseren. Als het geheugen geleegd is dan is deze (vrijwel) niet meer te herstellen of reconstrueren.
Omdat RAM dynamisch gegevens opslaat wordt het lastig om data in het geheugen terug te vinden. Deze bevind zich namelijk altijd op andere locaties binnen het RAM geheugen. Daarnaast, als extra veiligheidsmaatregel rouleert het OS de data ook binnen het RAM geheugen zodat zelfs binnen een sessie de data niet statisch is. Laten we eens wat beter kijken naar het geheugen. Het geheugen is namelijk ook opgebouwd uit bepaalde sectoren. Elk proces in een multitasking-OS wordt uitgevoerd in een zijn eigen memory sandbox. Deze sandbox kun je zien als een virtuele adresruimte welke door de CPU gegenereerd wordt. Deze adresruimte is in het geval van een 32-bits systeem altijd een blok van 4 GB geheugen adressen. Bij een x64-bits OS kan dit geheugenblok oplopen tot 16 TB.
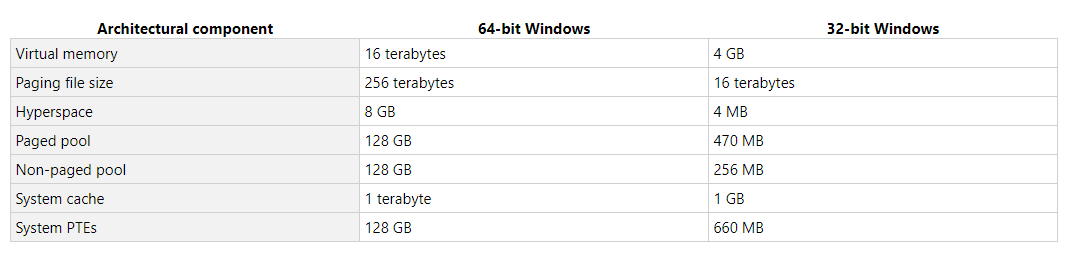
Voor het gemak gaan we in dit voorbeeld dus uit van een x32 OS. De kleinste unit die door de CPU kan worden geadresseerd is 1 byte (8 bit). Een x32 OS (en CPU) is dus in staat is om tot 2 ^ 32 – 1 “nummers” te genereren. Dus adressen die elk naar een specifieke byte in het geheugen verwijzen. Deze virtuele adressen worden vervolgens toegewezen aan echte, fysieke geheugenadressen middels paginatabellen die worden bewaard door de kernel van het OS.
Ok, eerst iets meer informatie over het virtuele geheugen ofwel de “pagefile”. Het doel van het virtuele geheugen is om geheugenadressen die door een actief programma zijn gegenereerd in kaart te brengen en om deze over te brengen (mappen) in fysieke adressen op het RAM geheugen. Dit proces wordt gekenmerkt door 2 subprocessen. 1, De adresvertaling van virtueel geheugen naar fysiek geheugen en 2, beheer op de virtuele adresruimte. het eerste proces wordt uitgevoerd door de MMU (Memory Management Unit) element welke op de CPU aanwezig is. Het tweede, beheer op de virtuele adresruimte wordt beheerd door het OS welke de virtuele adresruimtes indeelt (één virtuele ruimte voor alle processen of één voor elk proces) en in feite het echt RAM geheugen toewijst aan virtueel geheugen. De belangrijkste voordelen van virtueel geheugen zijn o.a. dat applicaties niet zelf de adresruimtes hoeven te beheren en dat de beveiliging verbeterd wordt doordat geheugenisolatie en het conceptueel meer geheugen kunnen gebruiken dan fysiek beschikbaar is met behulp van de paging-techniek (wachtrij). Bijna elke virtuele geheugenimplementatie verdeelt een virtuele adresruimte in blokken van aangrenzende virtuele geheugenadressen die we “pages” ofwel pagina’s noemen. Deze pagina’s zijn gewoonlijk 4 KB groot. Om virtuele adressen van een proces te vertalen naar fysieke geheugenadressen (RAM) en waar dus werkelijk de instructies verwerkt worden maakt de MMU een zogenaamde paginatabel. Een paginatabel is een door het besturingssysteem beheerde gegevensstructuur die toewijzingen tussen virtuele en fysieke adressen opslaat. De MMU slaat een cache op van alle recentelijk gebruikte toewijzingen welke opgeslagen wordt in de OS-paginatabel. Deze noemen we de TLB ofwel de “Translation Lookaside Buffer”.
Omdat de OS-kernel zelf een proces is bezet het een speciaal deel van de virtuele adresruimte. Dit deel is gescheiden van het gedeelte dat is gereserveerd voor de applicatieprocessen van andere gebruikers (niet OS-processen).
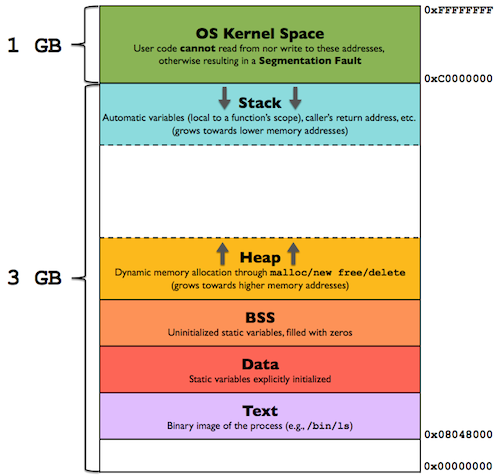
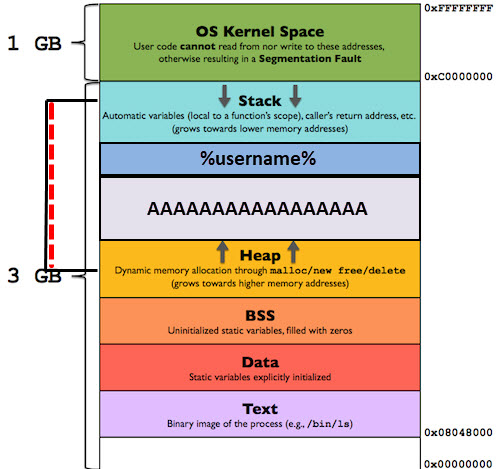
Bovenstaande afbeelding is een schematische weergave van een 4GB geheugenblok. je ziet hier dat de eerste 3 GB virtuele adressen (0x00000000 tot 0xBFFFFFFF) kunnen worden gebruikt voor gebruikersprocessen, terwijl de laatste 1 GB aan virtuele adressen (0xC0000000 tot 0xFFFFFFFF) zijn gereserveerd voor de OS-kernel. Laten we eerst de voor deze post wat minder belangrijke sectoren bespreken:
- OS Kernel Space – Dit gedeelte is gereserveerd voor OS / kernel processen en kan niet worden gelezen en er kan ook niet naartoe worden geschreven. In dit gedeelte bevinden zich de command-line parameters welke doorgestuurd worden naar programma’s.
- BSS – Dit is het “Uninitialized Data Segment”. Gegevens in dit segment worden door de OS-kernel geïnitialiseerd op “0” voordat het programma wordt uitgevoerd. Dit segment begint doorgaans aan het einde van het gegevenssegment en bevat alle globale en statische variabelen die zijn geïnitialiseerd op 0 of die geen expliciete initialisatie in de broncode hebben. Denk hierbij aan een variabele die als statisch int i is gedefinieerd. Het BSS-segment kan gelezen en beschreven worden.
- Data – In tegenstelling tot het BSS segment bestaat het Data segment uit waardes die wel gedefinieerd zijn. Daarom noemen we het data segment ook weleens het “Initialized data segment”.
In dit gedeelte vinden we de globale en statische variabelen terug. Binnen het data segment bestaat een “RoData” segment ofwel een “Read Only” data segement en een RWData segment ofwel een gedeelte dat leesbaar en herschrijfbaar is. Het RoData segment bevat b.v. de gedefinieerde constante variabelen en het RWData segment bevat de variabelen die bij en na runtime nog aangepast kunnen worden. - Text – Het text segment noemen we ook wel het “code segment”. Dit text segment het gedeelte in het geheugen welke de uitvoerbare instructies van een programma bevat (de werkelijke code). Normaal gesproken is de content in het text segment “sharable” wat betekend dat er slechts een enkele kopie in het geheugen hoeft te zijn en dat alle programma’s, teksteditors, de C-compiler, de shells, enz. hier gebruik van kunnen maken. Het text segment is een read-only segment om te voorkomen dat programma’s bepaalde instructies wijzigen welke impact heeft op andere applicaties.
De belangrijke 2 onderdelen bij een buffer overflow zijn de Stack en de Heap segmenten.
- Stack – De “Stack”, in het Nederlands vertaald naar “het stapelgebied” bevat de program stack (programmastapel) en werkt volgens een LIFO-structuur (last in – first out). De stack bevindt zich in de hogere geheugenadressen direct onder de OS-kernelruimte welke alleen gescheiden is middels een constante offset (Random Stack Offset). De stack groeit op een standaard x86-architectuur naar beneden richting de lagere adressen. Het kan echter zo zijn dat andere architecturen de stack andersom laten groeien. De stack sector is bedoeld om alle gegevens op te slaan die nodig zijn voor een functieaanroep in een programma. De set aan functies die gebruikt wordt voor 1 programma function call noemen we een “stack frame” ofwel een “stapelframe”. Een stack frame bestaat uit alle automatische variabelen en het return adres (waar moet het programma naartoe gaan als deze set is uitgevoerd). Zie een stapelframe als een set van alle automatische variabelen welke aangeroepen wordt binnen functie zoals de parameters. Op deze manier kan een set variabelen binnen één aanroep (stapelframe) volledig onafhankelijk functioneren van een andere functieaanroep. Al deze stapelframes worden bijgehouden door het “stack register” ofwel het stapelwijzerregister. Dit stapelregister bevindt zich aan de bovenkant van de stapel en berekend welke hoeveel van het stapelgebied een proces momenteel gebruikt. Deze hoeveelheid wordt aangepast wanneer er en nieuw stapelframe op de stapel wordt “geduwd”. Als de stack pointer de heap pointer ontmoet (of als het uiteindelijk de limiet van RLIMIT_STACK bereikt), is het vrij beschikbare geheugen benut en vol.
- Heap – Het heap segment is het segment waar normaliter de dynamische geheugentoewijzing plaatsvindt (dynamisch geheugen). Met dynamische geheugentoewijzing bedoelen we het gevraagde geheugen dat toegewezen wordt aan variabelen waarvan de grootte alleen tijdens de runtime bekend is en niet statisch kan worden bepaald door de compiler voordat het programma wordt uitgevoerd. Het heap segment begint aan het einde van het BSS segment en groeit naar de hogere geheugenadressen. Alle gedeelde bibliotheken en dynamisch geladen modules binnen een proces delen de heap sector.
Zo, dat was een kleine omschrijving van de verschillende segmenten en ook wat droge kost. Nu het echter werk… de buffer overflow.
Buffer Overflow
We hebben hierboven gezien dat wanneer de stack wordt aangevuld met nieuwe stack-layers dat deze naar beneden groeit. De stack benaderd dan low memory addresses en groeit richting het heap segment. Normaliter wanneer een functie aangeroepen wordt zullen de parameters een nieuwe stack layer vormen en bovenop de stack gepushed worden. Na het uitvoeren van de functie zal het programma terugkeren naar zijn oorspronkelijke geheugenadres alwaar hij verder gaan mijn de overige werkzaamheden. Wanneer een buffer overflow optreedt zal bestaande data overschreven worden waardoor het programma instabiel kan worden of informatie retourneert welke niet geretourneerd had mogen worden.
Ik denk dat het makkelijker is met een voorbeeldje.
*Onderstaande voorbeeld en screenshot is afkomstig van https://0xrick.github.io.
#include <stdio.h> int main () { char username[20]; printf("Enter your name: "); scanf("%s", username); printf("Hello %s\n", username); printf("Program exited normally"); return(0); |
Bovenstaande code doet iets simpels. Het vraagt namelijk de gebruiker om zijn naam. De gebruiker tikt deze in en de naam wordt als variabele in het geheugen opgeslagen. Deze applicatie raakt de volgende onderdelen in het geheugen:
- Text – In dit gedeelte wordt de source code van de applicatie geladen tezamen met de “main instructions”.
- BSS – Hier worden de globale variabelen opgeslagen.*
- Stack – Hierin worden de lokale variabelen en function calls opgeslagen. In dit voorbeeld dus de “username” variabele. Ook het return adres wordt hier opgeslagen. De stack sector wordt groeit hiermee omlaag richting de lagere geheugenadressen.
- Heap – Hierin worden de dynamische gegevens opgeslagen zoals de username die ingevuld wordt. In de heap sector wordt een buffer gereserveerd van 20 (24 omdat we blijven werken met bits = 8) om de gebruikersnaam op te slaan. De heap sector wordt hiermee omhoog gestapeld richting de hogere geheugenadressen.
*Het verschil tussen een “local variables” en een “global variables” is dat een lokale variabele beperkt is tot een bepaalde functie. Het is gedefinieerd in die functie en kan alleen in die functie worden aangeroepen. Een globale variabele wordt ofwel gedefinieerd in de hoofdfunctie of gedefinieerd buiten een functie en dit type variabelen kan overal worden aangeroepen.
Dit ziet er schematisch als volgt uit:
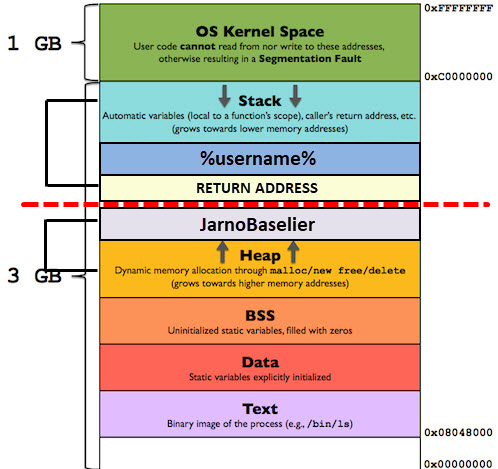
Normaliter zal het programma starten, vragen om de gebruikersnaam. Deze gebruikersnaam tonen en vervolgens de melding tonen dat het programma succesvol is uitgevoerd. De return code zorgt ervoor dat het programma na het ophalen van de “username” variabele terug gaat naar het programma en de rest uitvoert. Let op, de buffer waarin de gebruikersnaam wordt opgeslagen wordt gezet op 20 karakters. Wanneer er echter een gebruikersnaam opgegeven wordt welke langer is dan 20 karakters wordt de gereserveerde buffer overschreven waardoor het een andere geheugenplaats overschrijft en een “Segmentation fault” retourneert. De “Segmentation fault” treedt op omdat het return address overschreven is en de applicatie niet meer weet waar hij “verder moet gaan”. De applicatie zal op dit moment crashen. Een segementation fault treed ook op wanneer de applicatie geheugen betreed waar deze geen rechten toe heeft.
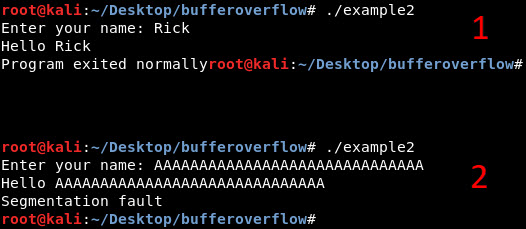
In bovenstaande voorbeeld zien we een basis buffer overflow. Schematig ziet dit er dan als volgt uit:
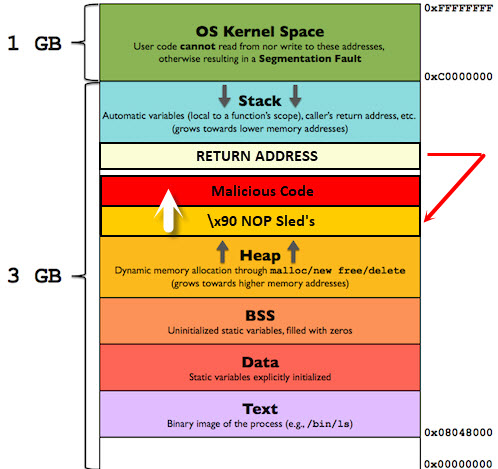
Zoals je ziet is de buffer out-of-bounds gegroeid en heeft hiermee het ”return adres” overschreven.
Dit gegeven veroorzaakt dus een programma crash. Dat is vervelend. Maar een buffer overflow kan nog veel meer negatieve gevolgen hebben zoals het uitvoeren van malafide (shell)code. Stel je voor dat je in de buffer een malafide code laad. Om deze code te starten moet je exact het juiste geheugenadres aangeven. Deze weet je echter niet. Hier komen de zogenaamde ”NOP Sled’s” van pas. Een NOP Sled wordt aangegeven met het hexadecimale karakter ”\x90″ en betekend simpelweg ”voer de eerst opvolgende waarde uit”. Dit is zeer waardevol. Want nu kun je een aantal NOP Sled’s wegschrijven. Het maakt niet uit waar de buffer exact gelezen wordt zolang deze op een NOP Sled land. Daarna wordt de (malicious) shellcode gestart en uitgevoerd. De NOP Sled’s verhogen dus de kans dat een programma op de malafide code land en deze uitvoert.
Dit is in de basis een “buffer overflow”. Echter hebben de CPU en het OS tegenwoordig diverse beveiligingen in-place om zo’n gemakkelijke buffer overflow een stuk lastiger te maken. Daarnaast werken x32 en x64 systemen niet hetzelfde en is een buffer overflow veroorzaken bij een x64 systeem wat lastiger. Belangrijk om een buffer overflow te begrijpen is dat je ook weet wat er binnen de stack layers gebeurt en met welke verschillende registers het geheugen werkt. Registers zorgen ervoor dat de CPU weet welke waarde hij na de huidige waarde moet uitvoeren. Laten we eerst eens kijken wat er zich bevindt in een stack layer:
Elk stack frame bestaat minimaal uit de volgende gegevens:
- Return Value
- Arguments
- Administrative properties
- Local variables
Maar om al deze gegevens te kunnen benaderen maakt het geheugen gebruik van verschillende pointers / registers. Bijvoorbeeld:
- EIP = Pointer naar de volgende instructie nadat deze instructie voltooid is
- RBP = Basis adres van het huidige stack frame
- RSP = Memory adres van te top van de stack
- ESP = Current Stack Pointer. Dit is een pointer naar het huidige adres.
- EBP = Wanneer een functie wordt aangeroepen wordt wat ruimte gereserveerd op de stack voor lokale variabelen. Dit noemen we de EBP.
- EDI = Doel index voor string operaties welke gebruikt wordt bij het kopiëren van memory en array.
- ESI = Bron index voor string operaties welke gebruikt wordt bij het kopiëren van memory en array.
- EDX = Vergroot de precisie van de accumulator (ook wel dataregister genoemd). In de praktijk zie je EAX en EDX door elkaar gebruikt worden bij 64-bits bewerkingen met 32-bits code.
- ECX = Counter (loop / string counter)
- EBX = Basis Index. Deze wordt gebruikt om interrupted return values op te halen, maar vertegenwoordigt over het algemeen de basis van de invoer die je in het geheugen opslaat.
- EAX = De accumulator wordt gebruikt voor toegang tot I / O-poorten, rekenkundige bewerkingen en onderbreken van oproepen.

Binnen een 64-bits architectuur bestaan dezelfde pointers maar deze dragen dan i.p.v. een E een R, dus: RIP, RBP, RSP, RBP, RDI, RSI, RDX, RCX, RBX en RAX.
Laten we weer eens een voorbeeldje nemen. De volgende code:
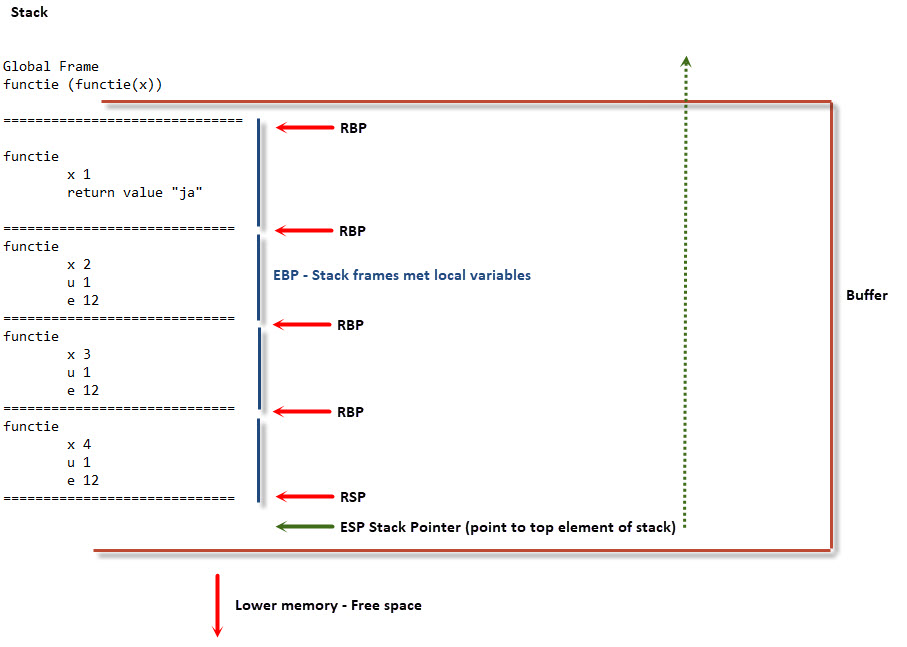
def functie(x): if x==1: return "ja" else: u=1 e=12 s=functie(x-1) e+=1 print(s) print(x) u+=1 return e functie(4) |
Hier definiëren we een functie genaamd “functie”. Als variabele x gelijk is aan 1 dan retourneert de applicatie “ja”. Als dat niet zo is dan worden een 4-tal nieuwe variabelen gedefinieerd, geprint en vervolgens wordt een return commando gegeven. Deze functie wordt 4x uitgevoerd.
- x = parameter waarvan de waarde doorgestuurd worden naar functie. In dit voorbeeld de waarde (argument) 4.
- u & e = lokale variabelen welke alleen binnen deze functie bestaan.
- s = Slaat de return value op van de vorige functie.
- 4 = argument
Bij iedere run van de applicatie zal er een stack frame gegenereerd worden.
Tenslotte is het belangrijk om te weten dat er verschillende data operators zijn in het geheugen, namelijk:
- mov – De ”mov” instructie kopieert het gegevensitem waarnaar wordt verwezen door zijn tweede operand (registerinhoud, geheugeninhoud of een constante waarde) naar de locatie waarnaar wordt verzwezen door zijn eerste operand (register of geheugen). Hoewel bewegingen van register naar register mogelijk zijn, zijn directe bewegingen van geheugen naar geheugen dat niet. In gevallen waarin geheugenoverdracht gewenst is, moet de inhoud van het brongeheugen eerst in een register worden geladen en vervolgens op het bestemmingsgeheugenadres worden opgeslagen.
- push – De ”push”instructie plaatst de operand op de bovenkant van de stack. Push verlaagt eerst de ESP waarde met 4 en plaatst dan zijn operand in de inhoud van de nieuwe geheugenlocatie (stack layer). ESP (de stack pointer) wordt verlaagd door push omdat de x86-stack naar beneden groeit. Door de ESP te verlagen groeit de stack en komt er dus ruimte vrij.
- pop – De pop-instructie verwijdert het 4-byte gegevenselement van de stack in de gespecificeerde operand (register of geheugenlocatie). Het verplaatst eerst de 4 bytes die zich op deze geheugenlocatie bevinden naar het gespecificeerde register of de geheugenlocatie, en verhoogt vervolgens SP met 4. De pop instructie is dus het tegenovergestelde van een push instructie. Zie de pop instructie als het verwijderen van gegevens en de push instructie als het plaatsen van gegevens.
- lia – Lia staat voor ”Load Effective Address” en plaatst het adres dat is gespecificeerd door de tweede operand in het register welke is gespecificeerd door de eerste operand. Let op, de inhoud van de geheugenlocatie wordt niet geladen, alleen het effectieve adres wordt berekend en in het register geplaatst. Dit is handig voor het verkrijgen van een pointer in een geheugengebied.
- call – De “call” instructie implementeert een subroutine-call en keert terug. De aanroepinstructie duwt eerst de huidige codelocatie op de stack (net zoals push) en springt vervolgens naar de codelocatie welke wordt aangegeven door de labeloperand. De locatie op waarnaar moet wordt teruggekeerd wordt opgeslagen zodat het programma door kan gaan met zijn vervolgacties wanneer de subroutine is voltooid.
Wanneer je het allemaal nog een beetje hebt kunnen volgen dan zou je nu het volgende stukje assebly code gedeeltelijk moeten kunnen begrijpen:
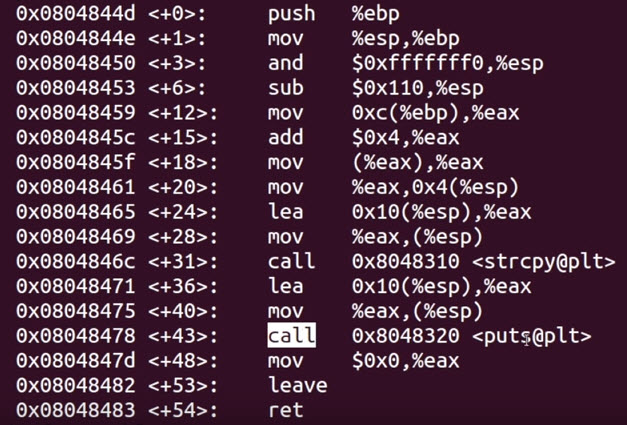
- 1- push ebp – Bewaard de oude waarde van de base pointer
- 2 – mov esp, ebp – Zet de waarde voor de nieuwe base pointer
- 4 – sub esp – Maak ruimte voor een 34-byte local variabele
- 5 – mov eax – Verplaats de waarde van parameter 1 in EAX
- 11 – call – Voer de instructies uit op de aangegeven geheugenlocatie
- etc.
Ben je er nog? Hopelijk heb je het een heel klein beetje kunnen volgen. Het is allemaal nogal taaie stof. De volgende keer gaan we een buffer overflow uitwerken en toepassen. Dan zal het vandaag besproken concept weer terugkomen en hopelijk meer verduidelijkt worden. Je hebt in ieder geval een goede idee van het computer geheugen en waar daarin zoal gebeurt. Vond je dit een interessante post… please give me some credit. Dat kan met een simpele like, een re-share of door het posten van mijn content op je eigen pagina! Deze acties geven me meer exposure en dus nog meer zin om nieuwe artiekelen te maken. Thanks-a-million!