





Autopsy – The Forensic Bloodhound
Autopsy – The Forensic Bloodhound
Nu we toch in de forensische mood zitten met posts over o.a. Cryptolocker Onderzoek, Writeblockers en Paladin, kets ik er gewoon nog een tegenaan. Namelijk mijn favoriete gratis open-source tool, Autopsy. Autopsy wordt gebruikt door forensisch onderzoekers over de hele wereld waaronder door het leger en de overheid zelf. We gebruiken Autopsy om forensische data te onderzoeken zodat we bewijslast kunnen achterhalen en aantonen. In deze post kijken we wat dieper in de Autopsy keuken!
Autopsy is als het ware een grafische tool voor “The Sleuth Kit”. Tools uit “The Sleuth Kit” worden overigens niet alleen in Autopsy gebruikt maar in veel andere commerciële en niet-commerciële tools. The Sleuth Kit is een combinatie van verschillende command-line tools en een bibliotheek gebaseerd op C. The Sleuth Kit wordt gebruikt om volumes en data te analyseren en indien nodig data terug te halen. Dit is meteen ook de core functionaliteit van Autopsy.
De interface
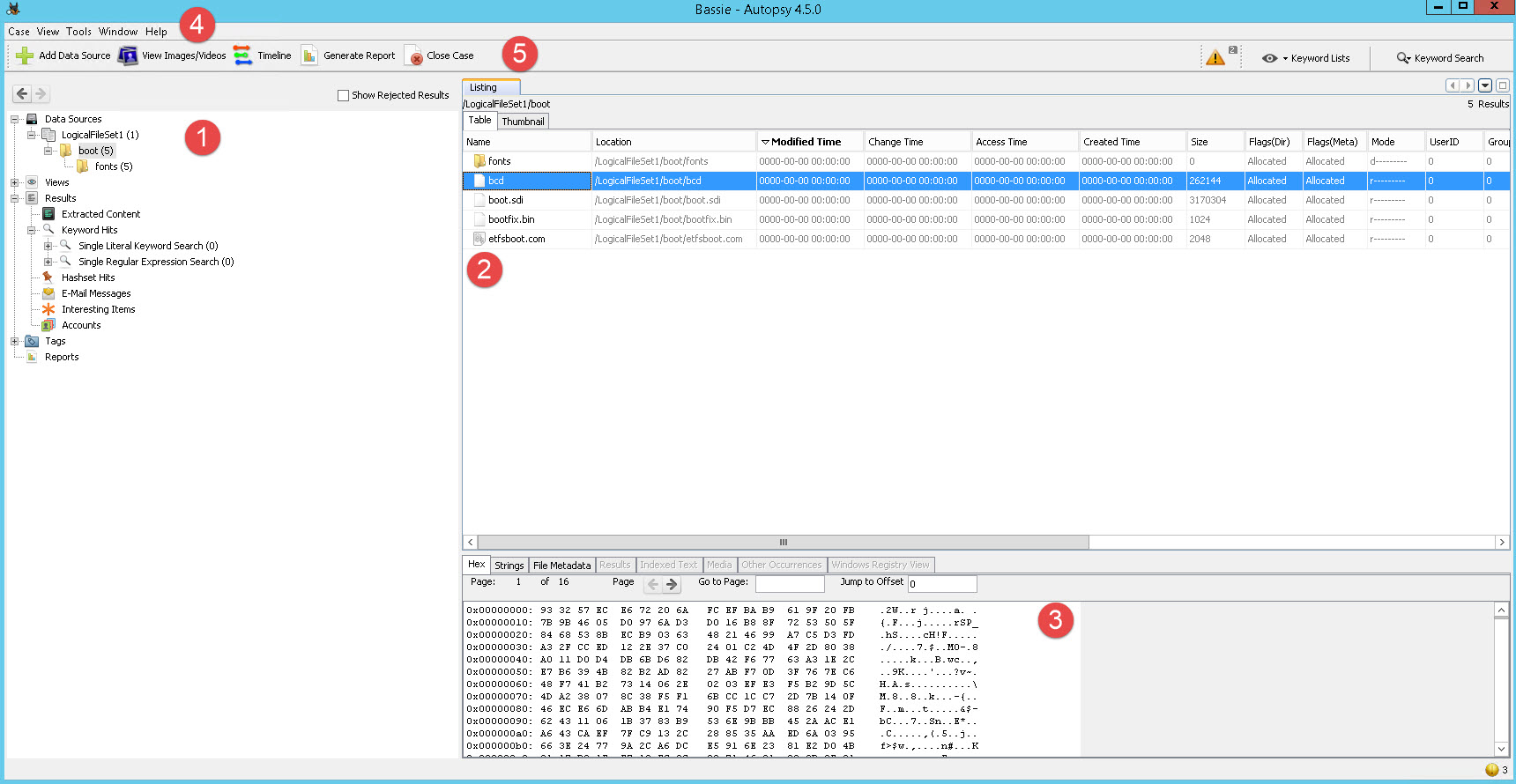
De interface van Autopsy bestaat default uit 3 panes. Links bevindt zich de “browse” pane waar je door mappen kunt bladeren. Daarnaast kent Autopsy nog een aantal verzamelingen die het zoeken wat makkelijker maken. Ook deze zijn aan de linkerkant te vinden. Rechts bovenin staat het resultatenvenster waar de resultaten zichtbaar zijn van o.a. zoekopdrachten, verzamelingen of de inhoud van folders. Rechts onderin bevindt zich de preview pane. In dit venster wordt de inhoud van bestanden weergegeven in o.a. HEX, Strings, Metadata, Indexed Tekst etc. De weergave van deze vensters is uit te breiden.
Verder staat bovenin de applicatie het menu waar de eigenschappen van de applicatie of je project aangepast kunnen worden. Daaronder bevindt zich de toolbar met een aantal knoppen. Door rechts op deze balk te klikken en te kiezen voor “customize” kun je zelf de knoppen in deze balk aanpassen door deze te slepen. Ook kunnen hier nieuwe toolbars worden aangemaakt. Tenslotte bevindt de zoekfunctie zich in deze balk.
De interface van Autopsy is redelijk straightforeward zonder al teveel functies en dit maakt de applicatie alleen maar sterker en duidelijker.
Formaten
Autopsy kan verschillende formaten importeren en onderzoeken. Uiteraard kunnen volumeimages en virtuele machines onderzocht worden. Denk aan de volgende formaten:
- IMG
- DD
- 001
- AA
- RAW
- E01
- BIN
- VMDK
- VHD
Uiteraard kunnen ook mounted disks, bestanden en unallocated space (ruimte op een disk welke niet tot een bekende partitie behoord) images onderzocht worden.
Als je een van deze volumes wilt onderzoeken kun je die aangeven tijdens het maken van je case of later toevoegen aan een bestaande case.
Je eerste Autopsy case
Om te starten met Autopsy moet je eerst een case aanmaken. Je case is een database waarin je eigenschappen en omstandigheden van de case worden bijgehouden en waarin de index resultaten van de volumes worden bijgehouden.
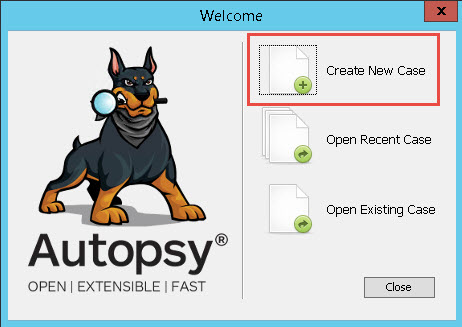
Om een case te starten kun je Autopsy starten en kies je voor “Create New Case”.
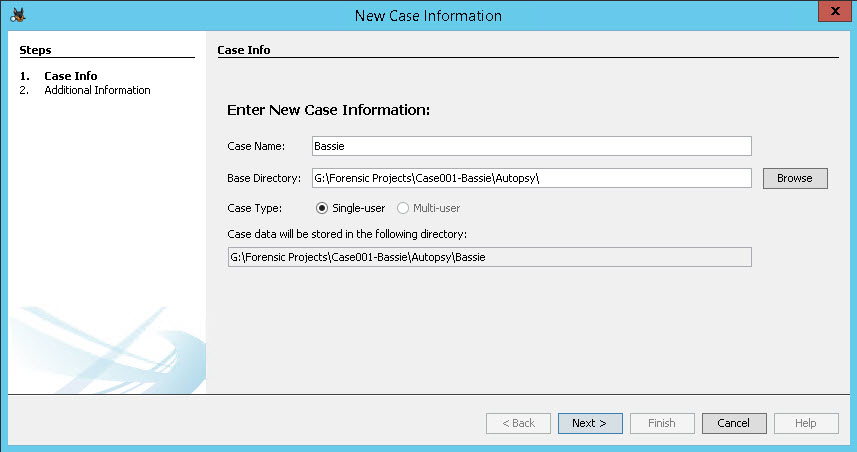
Vervolgens maak je een naam aan kies je de directory waar de Autopsy database opgeslagen wordt. Dan kun je er ook nog voor kiezen om met meerdere personen aan een project te werken. Om dit te doen moet je voor het maken van het project een multi-user omgeving opzetten waarbij centraal data en database settings aangemaakt worden.
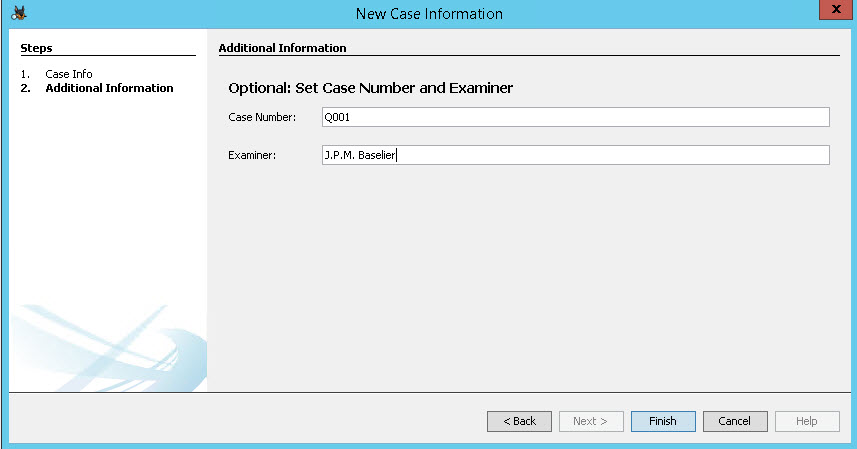
Daarna maak je een case nummer aan en geef je op wie de data onderzoekt:
Het project en de database wordt aangemaakt. Omdat je nog geen data hebt om mee te werken wordt gevraagd om een database in te lezen. Kies hier voor o.a. een disk image, VM of een logische disk:
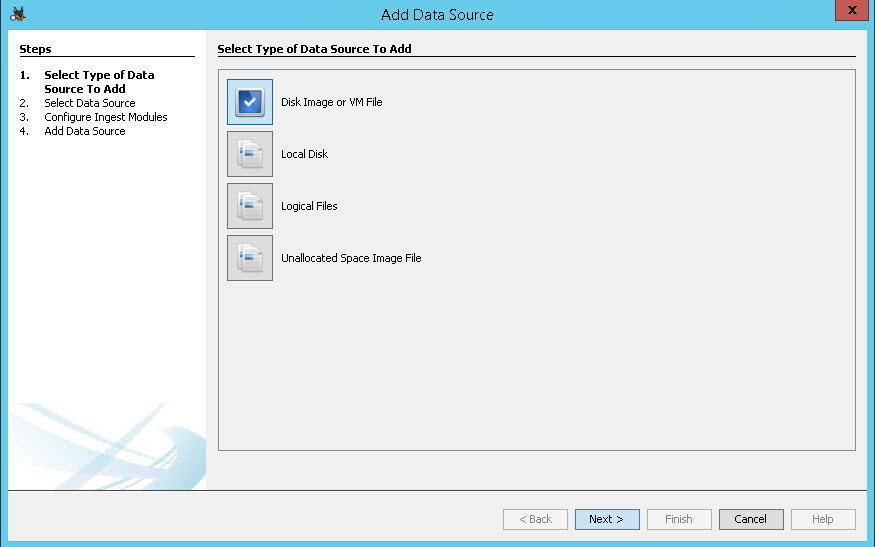
Na het selecteren van de databron kies je de “ingest modules”. Ofwel de modules / onderdelen die je data analyseren. Hoe meer modules des te langer het analyseren en indexeren zal duren maar hoe beter de zoekresultaten zullen zijn. Ook kies je welke data door de modules geïndexeerd gaat worden, alle bestanden en directories incl. of excl. unallocated space. Voorbeelden van ingest modules zijn o.a. hash calculation & lookup, keyword searching, en web artifact extraction. De ingest modules worden eerst toegepast op aanwezige gebruikersfolders en vervolgens op de overige data. Op deze manier kan snel relevante data gevonden worden.
Als je zelf een andere preset / ingest module wilt maken dan kan dat via “Create/Edit File Ingest Filters”
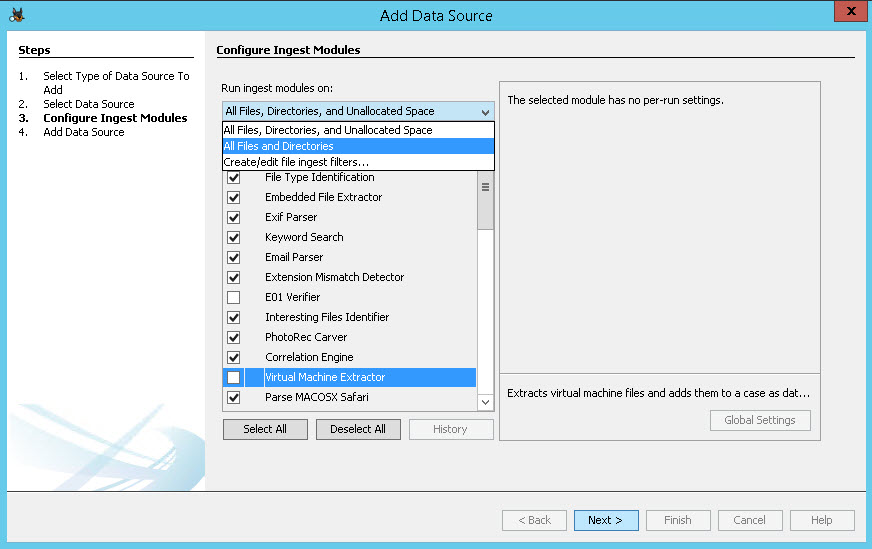
Vervolgens is de import klaar en start Autopsy met het indexeren van de data n.a.v. de zojuist gekozen ingest filters.
Je kunt later altijd andere ingest filters over de data draaien. Het toevoegen van een nieuwe databron aan het project doe je via Case – Add Data Source
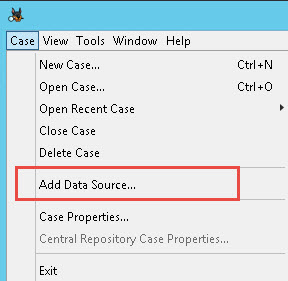
Als de data geanalyseerd en geïndexeerd is dan is je eerste project klaar voor gebruik.
Autopsy Plug-ins
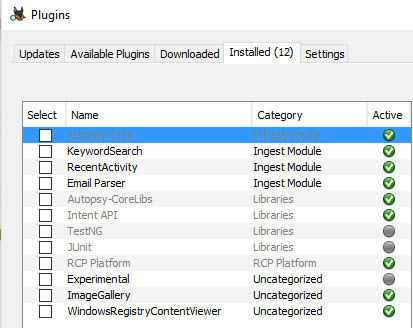
Autopsy Plug-ins maken Autopsy nog krachtiger. Zo zijn er plug-ins die registerbestanden analyseren, of plug-ins die Windows log files analyseren. Maar ook hashing en hash lookup modules of virusscan lookup, kindermisbruik lookup, video en image analyzers, Volatility memory scan en nog heel veel meer. De meeste van deze plug-ins zijn zogenaamde “ingest” modules welke data analyses doen of de gehele image of een gedeelte van de image en de resultaten hiervan opslaan in de database. Andere plug-ins zijn “click-and-use” plug-ins die gebruikt worden op het moment je deze nodig hebt.
Veel handige plug-ins zijn hier te vinden: https://wiki.sleuthkit.org/index.php?title=Autopsy_3rd_Party_Modules
Autopsy kent Java plug-ins verpakt in een “NetBeans Module” bestand welke geïnstalleerd worden binnen het Autopsy framework en Python plug-ins welke in een speciale plug-in folder geplaatst worden alvorens ze actief worden.
Zoeken
De belangrijkste functie is uiteraard de Autopsy zoekfunctie. Dat is immers het doel toch? Het doorzoeken van grote hoeveelheden data naar sporen of aanwijzingen. Autopsy gebruikt Apache SOLR voor het indexeren van bestanden en gebruikt daar bovenop krachtige modules zoals Tika om keywords te zoeken. Zoeken gaat dus niet alleen sneller dan raw data searches maar is ook nog eens ontzettend accuraat.
De zoekfunctie van Autopsy vinden we rechts bovenin.
![]()
Wanneer we gaan zoeken krijgen we 3 soorten zoekfuncties, namelijk “Exact Match”, “Substring Match” en “Regular Expression”.
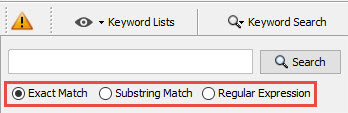
Zoeken op “Exact Match” betekend dat het woord wat gevonden moet worden ook exact gevonden wordt waarbij links en rechts non-word characters voorkomen zoals leestekens of whitespace (spatie of enter).
Zoeken met een “Substring Match” is bijna hetzelfde. Het exacte woord dat gezocht wordt moet voorkomen maar hoeft niet omgeven te zijn door non-word characters. Dus een zoekwoord mag ook onderdeel zijn van een langer woord. Zoeken naar hond zal dus ook “bloedhond” als resultaat genereren.
Zoeken met reguliere expressie (Regular Expression) is zeer krachtig. Met deze functie kan je zoeken met GREP Regular Expressions. Zo zal [Jj][Aa][Rr][Nn][Oo] elke schrijfwijze van “Jarno” als resultaat retourneren. Meer informatie over het zoeken met reguliere expressie kun je vinden in de Autopsy Grep Cheatcheat of in mijn regular expression tutorials: https://jarnobaselier.nl/reguliere-expressie-regular-expression-regexp-regex-re/.
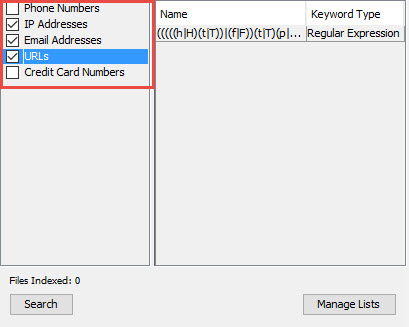
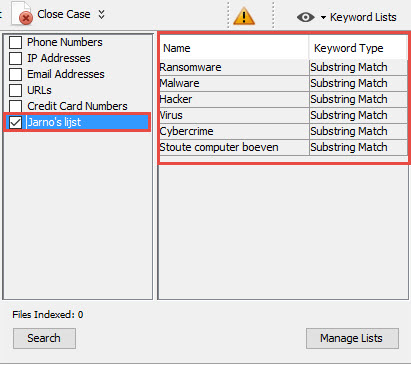
Autopsy heeft zelf al een aantal reguliere expressies waar standaard op gezocht wordt. Deze zijn te vinden onder de “Keyword Lists”:
![]()
Zo kun je aanvinken dat er gezocht wordt op IP adressen, URL’s, E-mailadressen en Creditkaartnummers. Wanner deze aangevinkt worden zal Autopsy deze nummers herkennen. Let wel, hier kunnen soms veel false-positives tussen zitten.
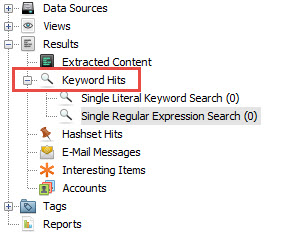
Resultaten zullen getoond worden onder de “Keyword Hits” aan de linkerzijde:
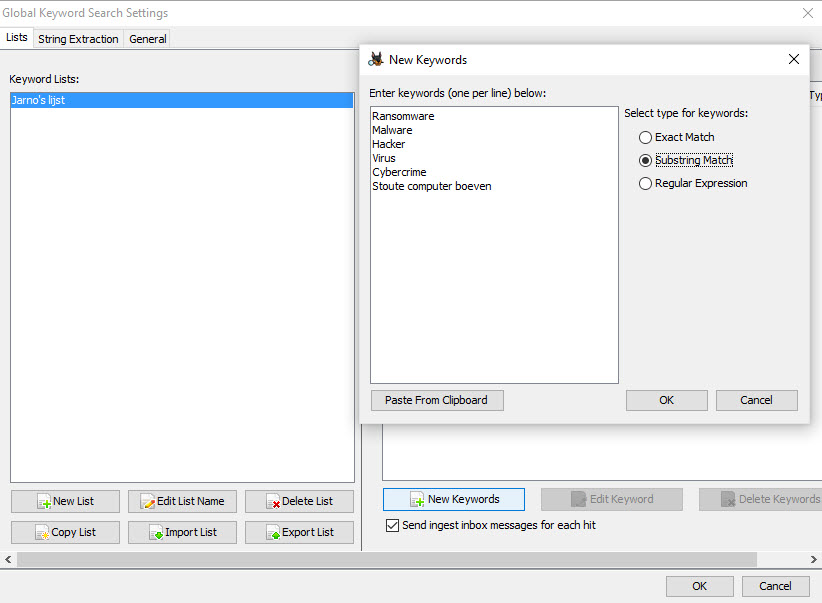
Maar je kunt ook je eigen lijsten samenstellen met zoekwoorden. Dit is makkelijk omdat je zo niet elk zoekwoord hoeft te onthouden en separaat hoeft te zoeken en Autopsy doorzoekt deze woorden meteen tijdens het indexeren van de data en dus is het een ontzettend snelle manier van zoeken. Deze keywoord lijsten kun je zelf maken via “Keyword Lists” – “Manage Lists”. Hier kun je verschillende keyword lijsten aanmaken en aangeven op welke manier je wilt zoeken. Je zou hier 3 lijsten kunnen maken voor b.v. “Exact Match”, “Substring Match” en “Regular Expression” zoekopdrachten.
Data Analyse
Wanneer bepaalde sleutelwoorden gevonden zijn is het zaak om de data te analyseren. Dit gebeurt in het onderste venster ofwel de preview pane (content viewers). Wanneer je een resultaat selecteert zie je onderin de data verdeeld over diverse tabbladen. Afhankelijk van additionele modules kunnen hier meer of minder tabbladen staan. De default tabbladen zijn:
- Hex
- Strings
- File Metadata
- Results
- Indexed Text
- Media
- Other Occurrences
Zoals je ziet zien mijn tabbladen er iets anders uit. Bij mij is het “Windows Registry View” tabblad toegevoegd omdat ik de “WindowsRegistryContentViewer” plug-in geactiveerd heb:
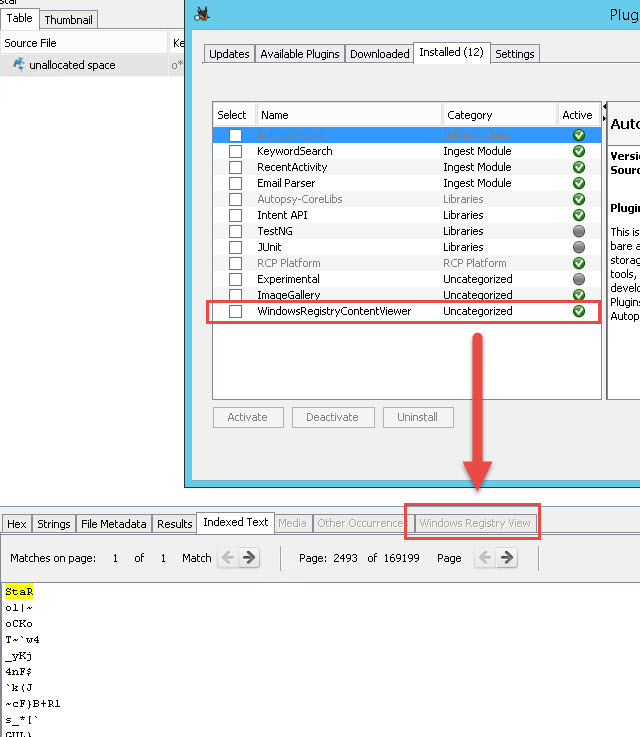
Hex Tab
De Hex tab laat de exacte inhoud van het bestand zien in “raw” formaat waarbij de exacte inhoud van het bestand te zien is. In deze viewer worden de hexadecimale waardes verdeeld in 2 groepen van 8 bytes gevolgd door een groep van 16 ASCII-tekens die zijn afgeleid van elk paar hex-waarden (per byte). Niet-afdrukbare ASCII-tekens en tekens die meer dan één tekenruimte innemen, worden meestal weergegeven als een punt in het volgende ASCII-veld
Strings Tab
De String Content Viewer scant gegevens van het bestand en doorzoekt deze op gegevens die mogelijk tekst (strings) zijn. Wanneer geschikte gegevens worden gevonden toont de String Content Viewer deze tekststrings.
De resultaten van de Strings Tab kunnen verschillen ten opzichte van de “Indexed Text” Tab omdat de tekst bij de “Indexed Text” tab afhankelijk is van een zoekwoordindex en metadata.
File Metadata Tab
De File Metadata Tab laat keurig leesbaar alle metagegevens van het bestand zien (indien deze aanwezig zijn). Denk aan b.v. de aanmaakdatum, auteur, formaat en MIME type.
Results Tab
De Results Tab is een content viewer voor de “artifacts” welke geassocieerd zijn met het bestand. De “artifacts” zijn de “opgeslagen resultaten” van een bestand. B.v. op welke termen dit resultaat gevonden is, waar het bestand zich bevind etc. Feitelijk de Autopsy Eigenschappen van het bestand.
Indexed Text Tab
Deze tab laat de tekstuele gegevens zien uit de zoekindex voor zoekwoorden die mogelijk is gevuld tijdens het opnemen van afbeeldingen. Als een bestand tekst bevat die is opgeslagen in de index, wordt dit tabblad ingeschakeld en wordt het weergegeven voor de gebruiker als een bestand of resultaat is geselecteerd dat aan een bestand is gekoppeld.
Dit tabblad bevat mogelijk meer tekst dan de “Strings Tab”, die afhankelijk is van het doorzoeken van het bestand naar tekstachtige gegevens (strings). Sommige bestanden, zoals PDF, zullen geen bytelevel-niveau hebben, maar het indexeringsproces van trefwoorden weet hoe een PDF-bestand moet worden geïnterpreteerd zodat er tekst uit onttrokken kan worden. Deze tab zal eveneens metadata van een bestand weergeven zoals auteur en aanmaakdatum.
Media Tab
De media tab laat mediabestanden zien. Denk hierbij aan afbeeldingen en video bestanden. Video’s kunnen worden afgespeeld. De formaten van de mediabestanden passen zich aan aan het vensterformaat.
Other Occurrences Tab
De Other Occurrences Tab is een content viewer welke gegevens weergeeft die in andere gevallen werden gevonden. Dus wanneer dit bestand ook in een andere gegevensbron of Autopsy Case is gevonden.
Conclusie
Om (forensische) data te onderzoeken is Autopsy absoluut de koning van de open-source tools. De kracht van de ingest indexatie, snelheid en modulaire optimalisatie zorgen ervoor dat Autopsy prima in staat is om data te onderzoeken. Zelfs intern geheugen (met module) en unallocated space zijn geen probleem voor deze toolkit. Autopsy – The Forensic Bloodhound!